Not all projects are present on the site to allow for better readability. Additionally, some projects are not relevant.
In this section, you will find an overview of projects that have been relevant to my professional and personal journey. Each project is described with its objectives, the challenges encountered, and the results achieved.
These projects have allowed me to develop various skills and gain further expertise. Feel free to contact me for more information or to discuss future collaborations.
1 - Development of a Portfolio and Presentation Website Based on the Hugo Framework
After completing my internship with my defense in September 2024, I began developing this site to showcase my projects and skills. This portfolio, built with the Hugo framework, highlights my professional and personal achievements.
Hugo is a modern static site generator framework, widely appreciated for its speed and simplicity. Here are some key points about Hugo:
Speed: Hugo is known for its ability to generate websites at an impressive speed, making it ideal for projects requiring frequent updates.
Simplicity: With Hugo, content creation is simplified through the use of Markdown files, allowing for easy and intuitive writing.
Flexibility: Hugo offers great flexibility with its theme and template system, allowing for extensive customization of the site’s design and functionality.
Active Community: Hugo benefits from an active community and comprehensive documentation, facilitating learning and troubleshooting.
Multilingual: Hugo natively supports the creation of multilingual sites, which is a major asset for international projects.
Hugo works by converting content written in Markdown and templates into static HTML.
Content Creation: Users create content using Markdown files, allowing for simple and efficient writing.
Templates and Themes: Hugo uses templates and themes to define the appearance and structure of the site. These templates are written in HTML and CSS, with additional features provided by Hugo.
Site Generation: When you run Hugo, it compiles the content and templates to generate a static website, ready to be deployed on a web server.
1.1 - Implementation of the Website
In this section, we will explore the technical aspects of the website, its development, and its deployment.
Development
One of the advantages of Hugo is the use of templates and themes that allow for site customization. To quickly develop the site, I used an existing theme, “Docsy.”
This theme is used for:
Content structure: Docsy provides a clear structure for organizing documents and sections of the site, making navigation easier for users.
Responsive design: The theme is designed to be responsive, ensuring a good user experience across different devices.
Built-in features: Docsy includes useful features like search, side navigation, and multilingual support.
During development, several key steps were followed:
Initial Setup: Installing Hugo and setting up the project with the Docsy theme.
Customization: Adapting the theme to meet the specific needs of the project, including modifying styles and templates.
Content Creation: Writing pages in Markdown and organizing sections.
Local Testing: Using hugo server to test the site locally.
Deployment
Once the first version of the site was developed, it needed to be hosted. One of the solutions recommended by Hugo’s documentation is to host it on GitLab. By creating a repository on GitLab, the site can be directly hosted there:
GitLab Repository Setup: Creating a new GitLab repository for the site and configuring deployment files.
CI/CD Setup: Using GitLab CI/CD to automate deployment. This includes creating a .gitlab-ci.yml file to define the build and deployment steps.
Hosting: Configuring GitLab Pages to host the site, making the content publicly accessible.
The .gitlab-ci.yml file used for deployment:
stages:- build- deployvariables:HUGO_VERSION:"0.137.1"GIT_SUBMODULE_STRATEGY:recursivebefore_script:- apt-get update && apt-get install -y wget curl golang- wget https://github.com/gohugoio/hugo/releases/download/v${HUGO_VERSION}/hugo_extended_${HUGO_VERSION}_Linux-64bit.tar.gz- tar -xzf hugo_extended_${HUGO_VERSION}_Linux-64bit.tar.gz -C /usr/local/bin- hugo version- curl -fsSL https://deb.nodesource.com/setup_18.x | bash -- apt-get install -y nodejsbuild:stage:buildscript:- if [ -f package.json ]; then npm install; fi- npm install -g sass- hugo --gc --minify --baseURL "$CI_PAGES_URL/"artifacts:paths:- publiconly:- mainpages:stage:deployscript:- echo "Deploying to GitLab Pages..."artifacts:paths:- publiconly:- mainenvironment:name:productionurl:$CI_PAGES_URL
Additionally, with hello.cv, I was able to purchase a domain with my name to make the site easier to access. This allows visitors to easily find my portfolio using a custom and professional URL.
During my study, I participated to innovative projects such as this one. This project aim at finding novels and explorings solutions to implement an incremental learning model including an active learning solution for emotion recognition (CFEE, Compound Facial Expressions of Emotion)
This project was proposed by the “Learning Data Robotics” (LDR) research laboratory of ESIEA. The supervision is provided by Lionel Prevost, University Professor, Director of the LDR (Learning, Data & Robotics) laboratory, and Khadija Slimani, Doctor, member of the LDR.
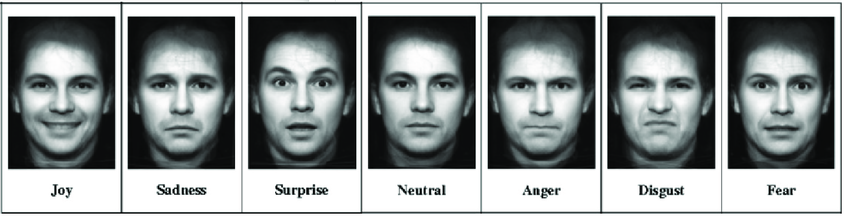
Emotion recognition is a well-known issue in artificial intelligence; affective computing aims to analyze human emotional states using video data to determine emotional states through non-verbal, paraverbal, and verbal cues.
The state of the art in this field mainly focuses on basic emotions (fear, anger, joy, surprise, sadness, and disgust as defined by Ekman). However, in many contexts, individuals rarely express these types of emotions and instead express complex emotions such as confidence or pride. Moreover, the interpretation of these emotions is not universal. The goal of our project is to improve classification by adding emotions to the model during the learning process.
One of the first tasks before exploring potential directions is conducting a state of the art. This section explains the key concepts explored during the literature review.
State of the Art
A state of the art involves conducting an exhaustive review of existing work on a given topic in order to understand the current advances, gaps, and trends in the field. It helps place the project within its scientific and technical context and identify innovation opportunities.
In our case, we focused the state of the art on Incremental Learning (IL) and Active Learning (AL). Other related or relevant concepts were also considered where appropriate.
Incremental Learning (IL)
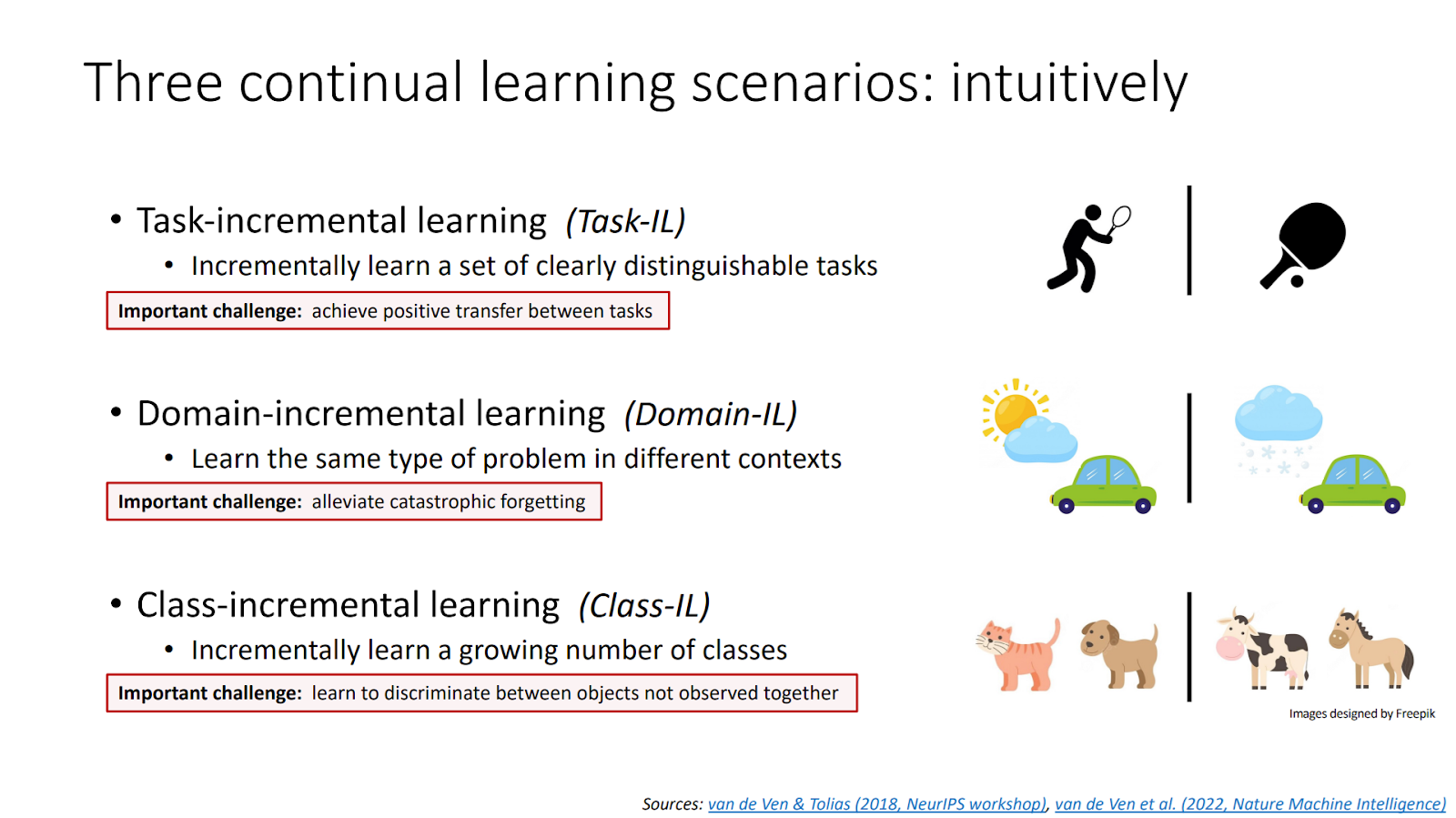
Incremental Learning (IL) allows a model to continuously learn from new data without retraining from scratch. Unlike traditional machine learning, IL updates its knowledge while retaining what was previously learned. It comes in three main forms: Task-IL, Domain-IL, and Class-IL, each suited to a particular type of data evolution.
Catastrophic forgetting is the main challenge in IL: new learning tends to overwrite old knowledge. Solutions include adapting random forests or using specific classifiers like Nearest Class Mean, which help mitigate this issue by balancing memory efficiency and robustness.
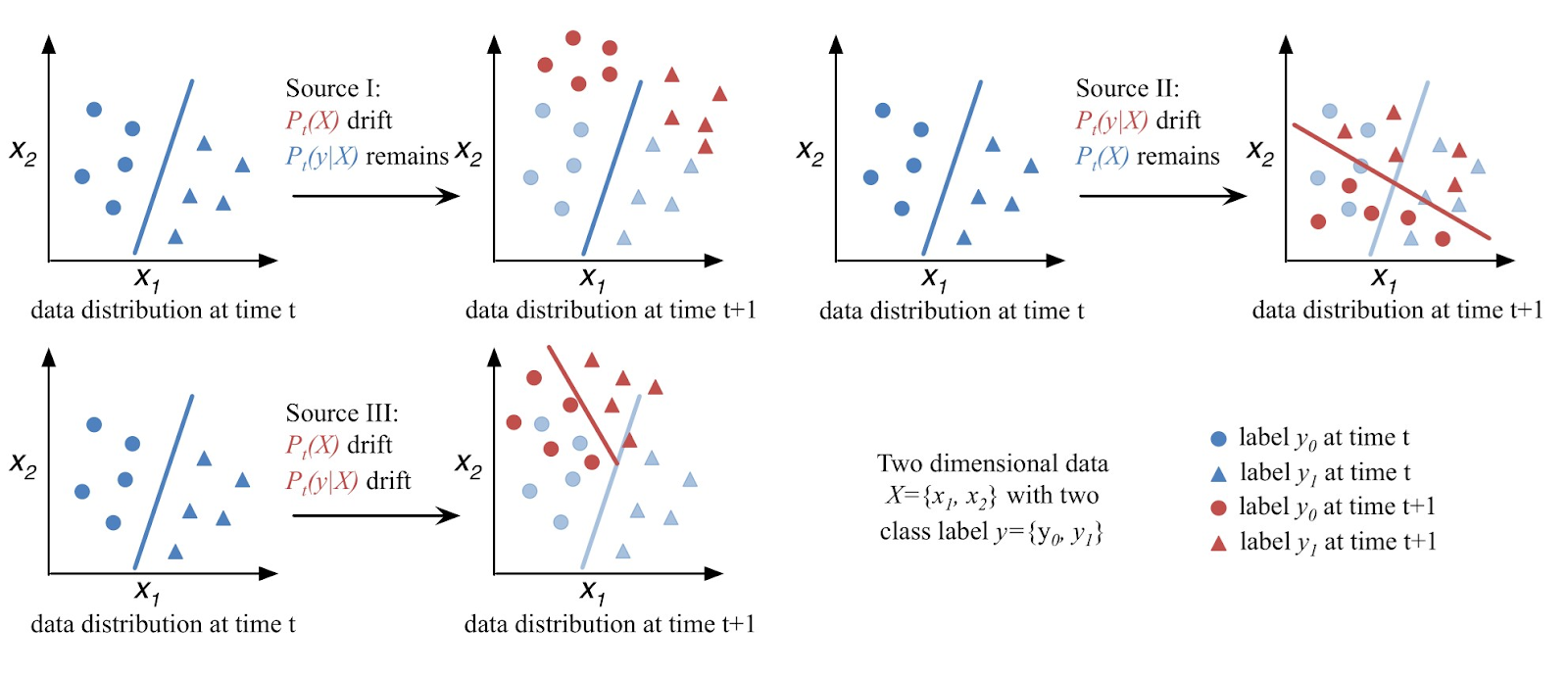
Concept drift refers to changes in data distribution over time, which degrades model performance if not detected. Drift can be virtual, real, or both. Types include sudden, gradual, incremental, or recurrent drifts. Techniques such as DDM, LSDD, and HCDT help detect drift by tracking errors or distribution changes.
Rehearsal and pseudo-rehearsal techniques aim to reduce forgetting. Rehearsal stores a subset of past examples in memory, while pseudo-rehearsal generates synthetic data using generators. The iCaRL model combines these with knowledge distillation to preserve old knowledge while learning new classes.
Active Learning (AL)
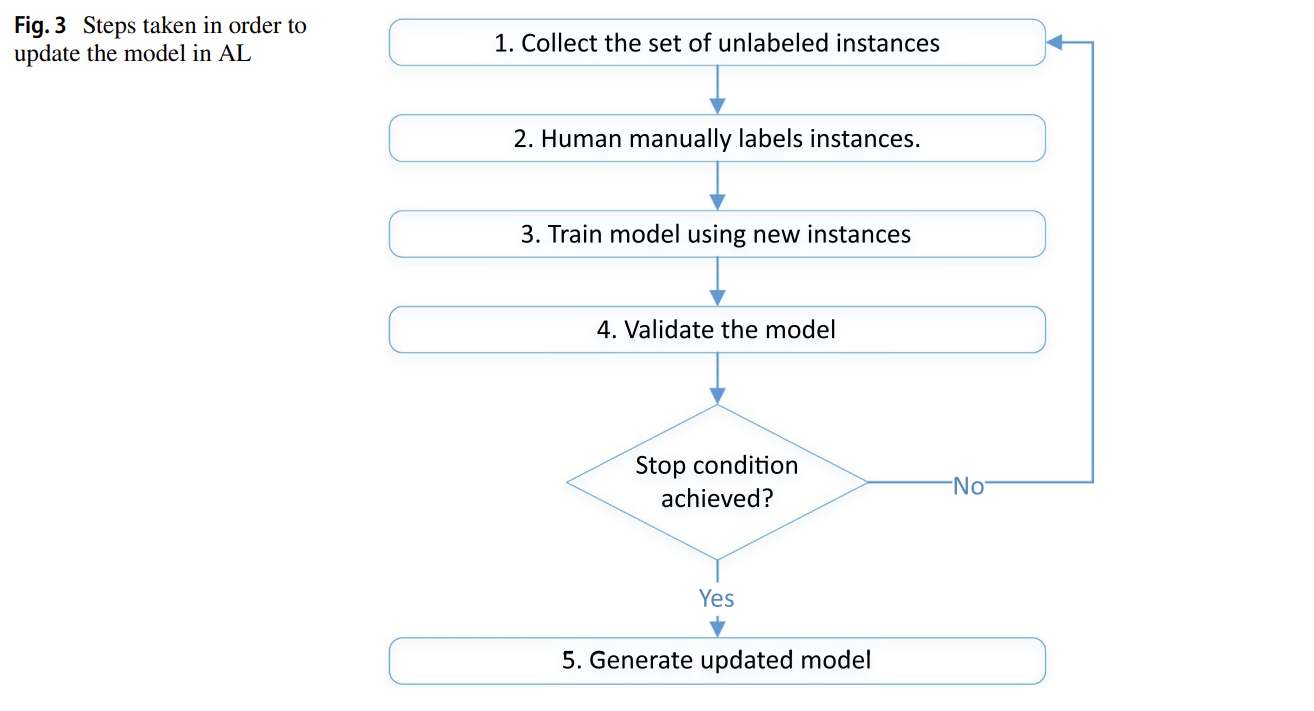
Active Learning involves human input in the training process: the model selects the most informative examples to be labeled. This allows it to maximize learning while minimizing labeling effort. Three common sampling strategies are used: random, uncertainty-based (ambiguous data), and diversity-based (representative examples).
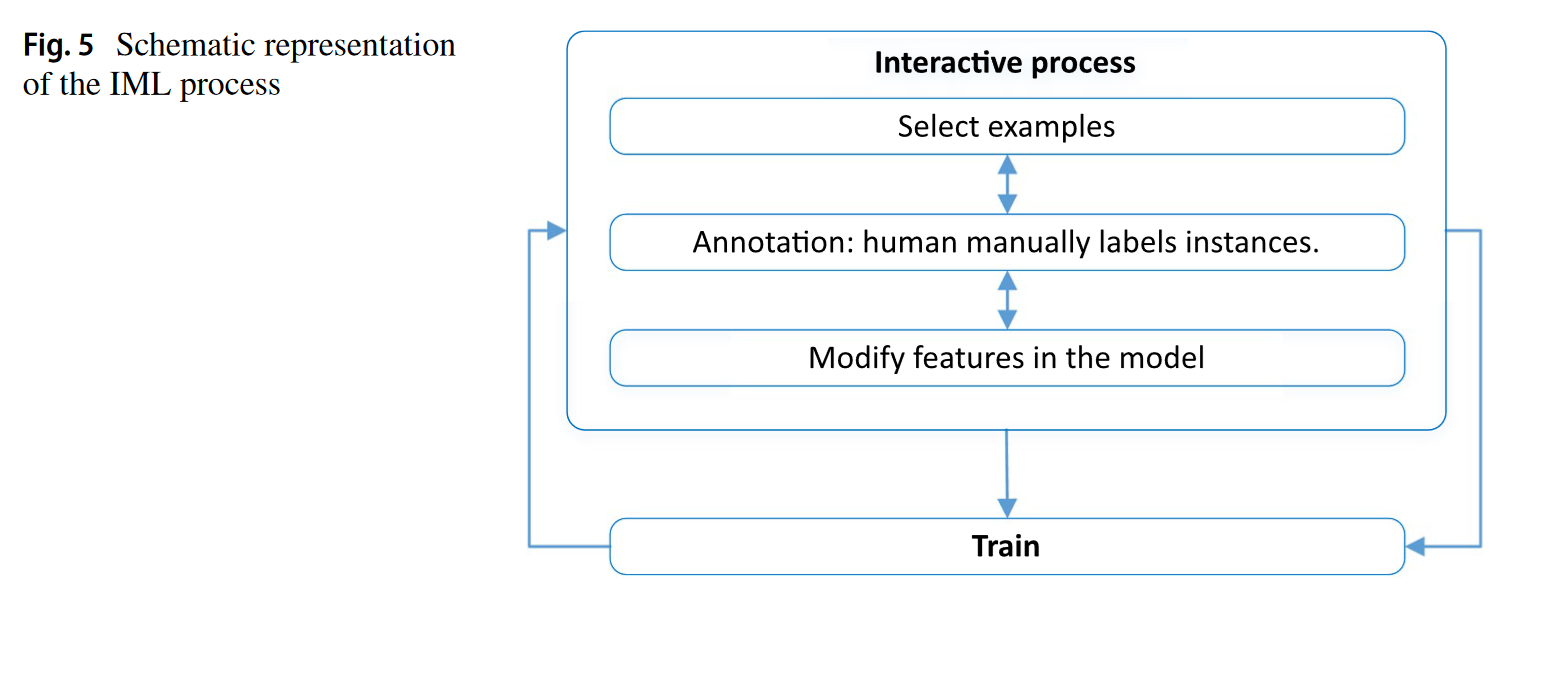
Interactive Machine Learning (IML) goes beyond AL by giving humans more control: they can choose which data to annotate and correct model predictions during training. This is useful when labeled data is scarce or when automation alone is insufficient, making AI more accessible to non-experts.
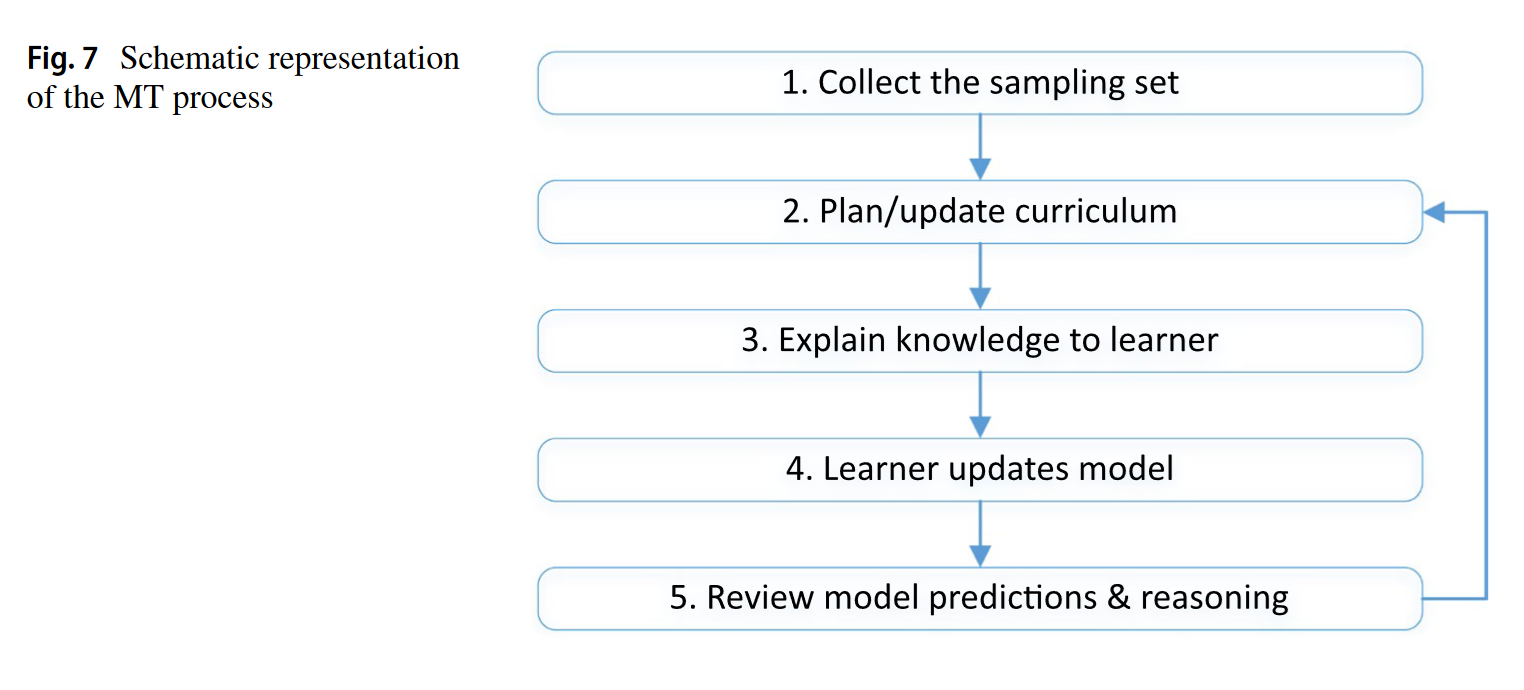
Machine Teaching (MT) gives the human (or another AI system) the role of a “teacher.” It controls which examples are shown, how they are labeled, and can even modify the features. This allows more precise guidance of the learning process, such as in systems like SOLOIST where users correct the model’s responses in real time.
This section is dedicated to the various explorations and ideas we developed to implement an incremental solution for emotion recognition.
Exploration and Research
After completing the state-of-the-art review, we identified several exploration paths, such as implementing an iCaRL model or other architectures suitable for incremental learning. Additionally, the CFEE (Compound Facial Expressions of Emotion) dataset was used in our project as a relevant base for training and evaluating our models.
CFEE (Compound Facial Expressions of Emotion)
The CFEE dataset consists of acted emotion images performed by volunteers. This introduces a possible bias, as the emotions are not spontaneous. It contains 22 emotions: the 6 basic Ekman emotions, the neutral emotion, and 15 complex emotions such as Happily_Disgusted or Sadly_Surprised, which are combinations of basic emotions.
This dataset is used to train and test our emotion recognition models incrementally.
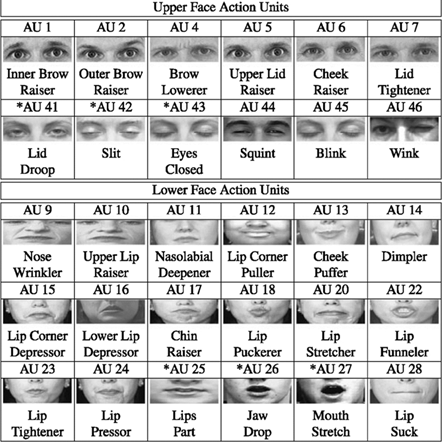
Action Unit (AU)
Action Units (AU) are measurements of facial muscle activation. They can be binary (on/off) or expressed as intensity values. AUs are automatically extracted using the OpenFace tool. Their advantages are that they are interpretable, compact, and well-suited for incremental models due to their low dimensionality.
The iCaRL model was mentioned in our state-of-the-art review as a reference for class-incremental learning. We explored its potential for our use case. However, its implementation requires complex management of exemplar sets, knowledge distillation, and custom architecture. Due to these constraints, iCaRL was not selected in our experimental pipeline in favor of simpler and more compatible solutions.
Autoencoder
Autoencoders are unsupervised neural networks capable of compressing and reconstructing data. We considered their use to extract compact features from images or to generate synthetic data (pseudo-rehearsal). This approach reduces storage needs while preserving useful representations for incremental classification.
Batching
In our project, batching refers to dividing the dataset into successive class batches. This simulates a class-incremental learning scenario, where new classes are introduced to the model progressively without access to previous data.
Two batching strategies were considered:
A grouped batch, starting with basic emotions, followed by batches introducing groups of compound emotions.
A unit batch, where each new class is introduced individually, simulating a more granular and controlled learning process.
This approach enables us to:
Evaluate the model’s robustness to catastrophic forgetting.
Measure the impact of each added class on overall performance.
Test techniques such as rehearsal and active learning in a controlled setting.
Existing Incremental Models
We tested several incremental models available in the scikit-learn library, including:
Multinomial Naive Bayes (MNB)
Perceptron (SGDClassifier)
Passive-Aggressive Classifier (PAC)
Bernoulli Naive Bayes (BNB)
Random Forests, adapted for batch mode
MLPClassifier, using controlled incremental updates
These models served as baselines, allowing rapid evaluation of incremental performance using AU data and feature vectors extracted from CNNs.
2.3 - Implementation
The final experimental implementation is based on incremental models from the scikit-learn library. These models use Action Units (AU) extracted from CFEE dataset images, as well as feature vectors from pre-trained models.
Implementation
We first compared several non-incremental models to establish a performance baseline. The most effective model across the 22 emotion classes was a Random Forest, achieving a score of 0.69. This step helped us evaluate how incremental models perform in our context. As previously mentioned, we use the CFEE dataset and extract Action Units (AU) using OpenFace.
In addition to AUs, we extracted advanced feature vectors using pre-trained models such as GoogleNet, ResNet, and MobileNet. These features enrich the input of classification models by providing more complex visual representations than AUs alone.
Incremental Models
For incremental learning, we used models from the scikit-learn library that support data input in batches, including:
Random Forest (adapted via partial_fit)
Perceptron (SGDClassifier)
Bernoulli Naive Bayes (BNB)
Multinomial Naive Bayes (MNB)
MLPClassifier (iterative batch updates)
Passive-Aggressive Classifier (PAC)
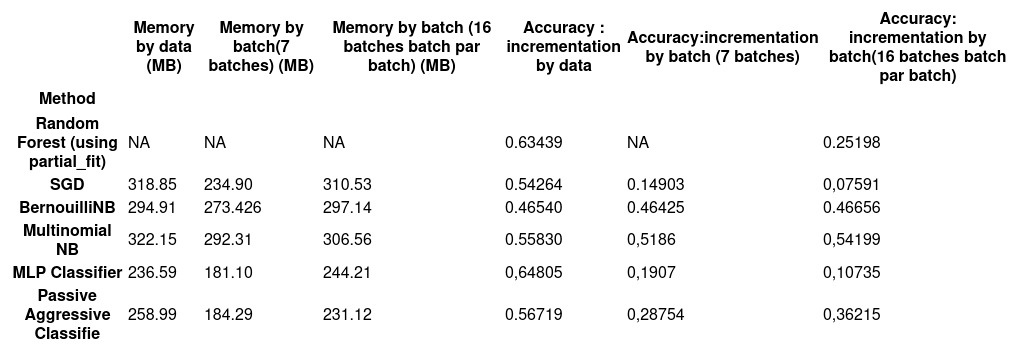
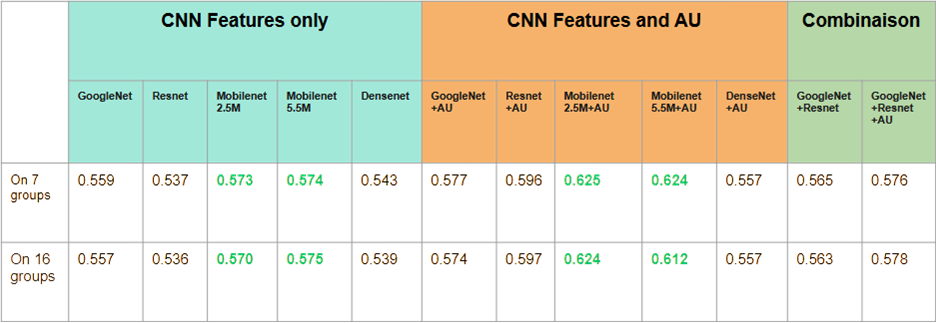
The performance of these models using only AUs is shown below:
These models were then tested using enriched input: AU + CNN features, to evaluate the impact of this combination.
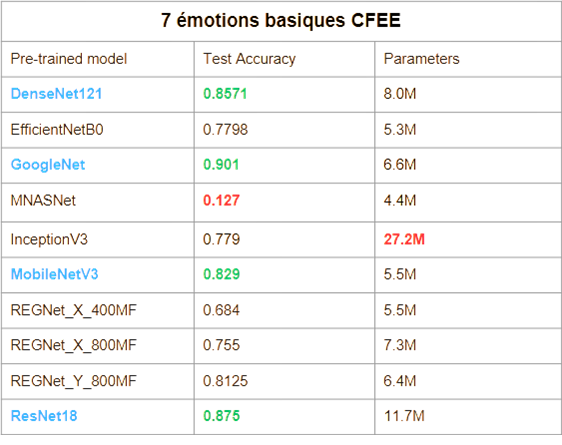
Pre-trained Models
We evaluated several CNNs pre-trained on ImageNet, applied to the 7 basic emotions (6 Ekman emotions + neutral). This restriction follows the incremental learning setup, where the model doesn’t have access to all classes from the start.
The purpose is to use these CNNs solely as feature extractors, removing their final classification layer.
The most effective models identified were:
DenseNet121
GoogleNet
MobileNet v3
ResNet-18
These networks convert CFEE images into feature vectors, and the final classification layer is removed. The resulting vectors are then concatenated with AU data and used as input for incremental models.
Final Implementation
The selected final approach combines Action Units with CNN features, using Multinomial Naive Bayes (MNB) as the classifier. This model gave the best results in our incremental experiments.
This architecture offers a good trade-off between accuracy, implementation simplicity, memory efficiency, and compatibility with class-incremental learning.
The final performance of the MNB model with different feature types is shown below:
Conclusion and Perspectives
Our incremental learning approach effectively addressed emotion recognition using the CFEE dataset, combining Action Units from OpenFace and visual features from pre-trained CNNs. The Multinomial Naive Bayes classifier emerged as the best fit for our setup, offering a solid balance between performance and simplicity.
However, several limitations were identified:
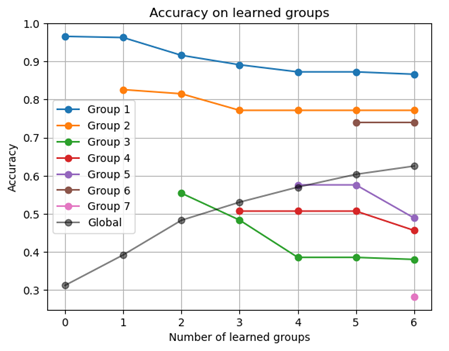
A catastrophic forgetting rate of about 10% on basic emotions.
Specific groups (3, 4, 5, 7) are harder to distinguish, likely due to less discriminative features.
Significant confusion between certain compound emotions, suggesting better class separation is needed.
These observations lead to promising future work directions:
Develop more refined methods to separate commonly confused classes, via deeper latent representation analysis.
Dynamically adapt the feature extractor CNN as new batches are introduced.
Implement intelligent rehearsal, selecting the most informative examples to retain.
Experiment with generative models (e.g., GANs, VAEs) for pseudo-rehearsal, to limit memory loss without storing real data.