State of the Art
State of the Art
A state of the art involves conducting an exhaustive review of existing work on a given topic in order to understand the current advances, gaps, and trends in the field. It helps place the project within its scientific and technical context and identify innovation opportunities.
In our case, we focused the state of the art on Incremental Learning (IL) and Active Learning (AL). Other related or relevant concepts were also considered where appropriate.
Incremental Learning (IL)
Incremental Learning (IL) allows a model to continuously learn from new data without retraining from scratch. Unlike traditional machine learning, IL updates its knowledge while retaining what was previously learned. It comes in three main forms: Task-IL, Domain-IL, and Class-IL, each suited to a particular type of data evolution.
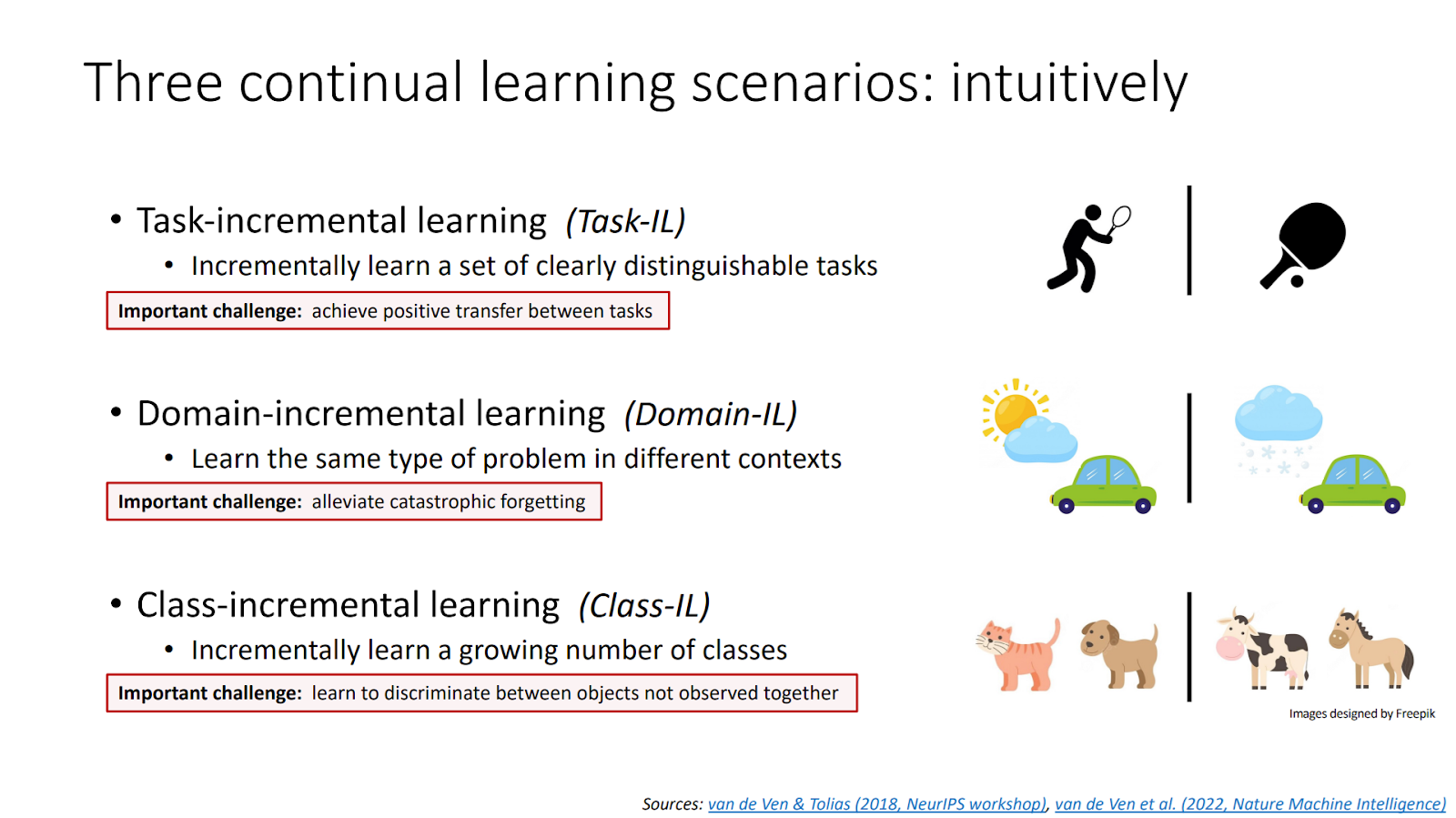
Challenges in Incremental Learning and Solutions
Catastrophic forgetting is the main challenge in IL: new learning tends to overwrite old knowledge. Solutions include adapting random forests or using specific classifiers like Nearest Class Mean, which help mitigate this issue by balancing memory efficiency and robustness.
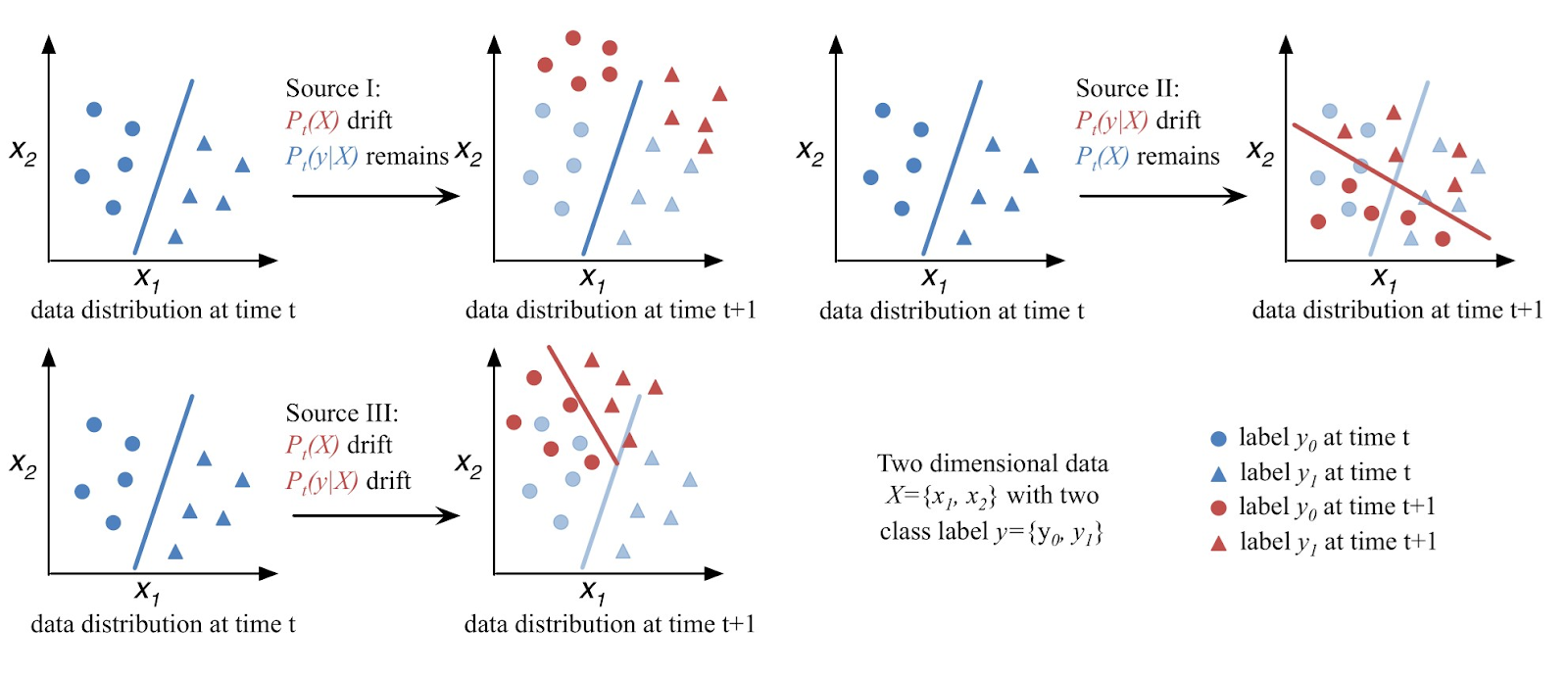
Concept drift refers to changes in data distribution over time, which degrades model performance if not detected. Drift can be virtual, real, or both. Types include sudden, gradual, incremental, or recurrent drifts. Techniques such as DDM, LSDD, and HCDT help detect drift by tracking errors or distribution changes.
Rehearsal and pseudo-rehearsal techniques aim to reduce forgetting. Rehearsal stores a subset of past examples in memory, while pseudo-rehearsal generates synthetic data using generators. The iCaRL model combines these with knowledge distillation to preserve old knowledge while learning new classes.
Active Learning (AL)
Active Learning involves human input in the training process: the model selects the most informative examples to be labeled. This allows it to maximize learning while minimizing labeling effort. Three common sampling strategies are used: random, uncertainty-based (ambiguous data), and diversity-based (representative examples).
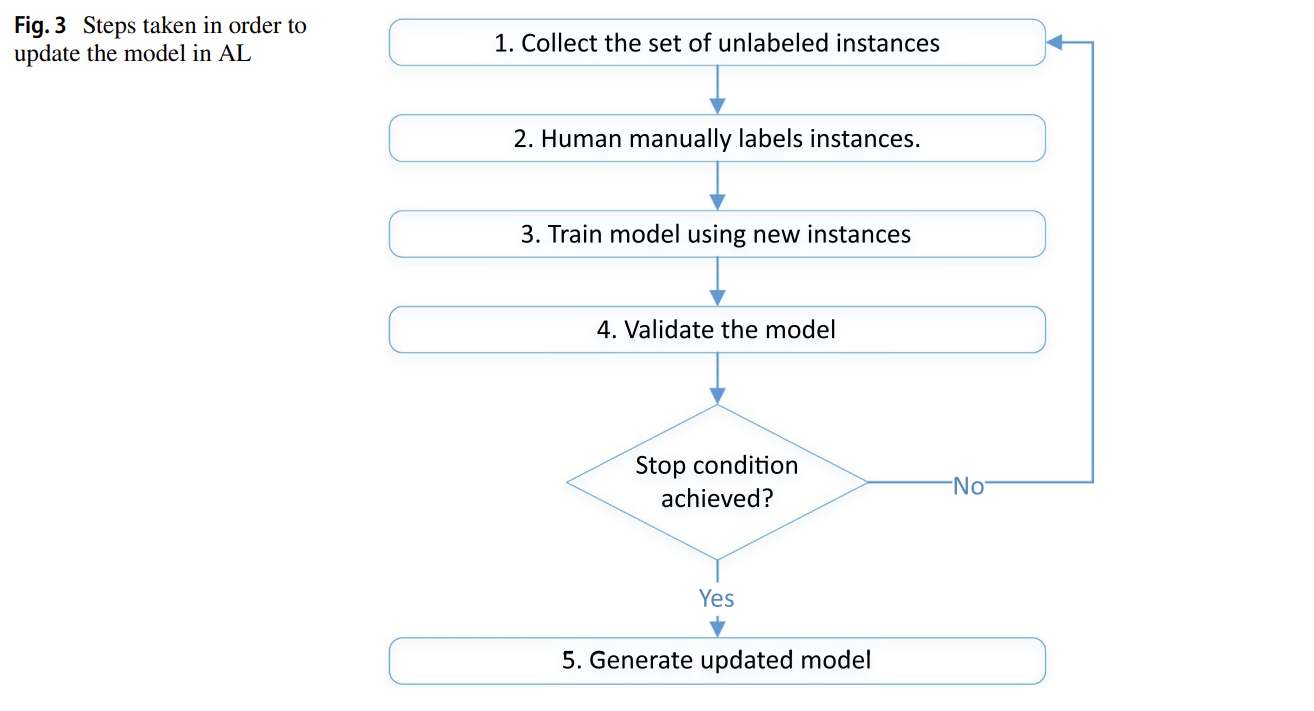
Source: A Survey of Deep Active Learning
Interactive Machine Learning (IML) goes beyond AL by giving humans more control: they can choose which data to annotate and correct model predictions during training. This is useful when labeled data is scarce or when automation alone is insufficient, making AI more accessible to non-experts.
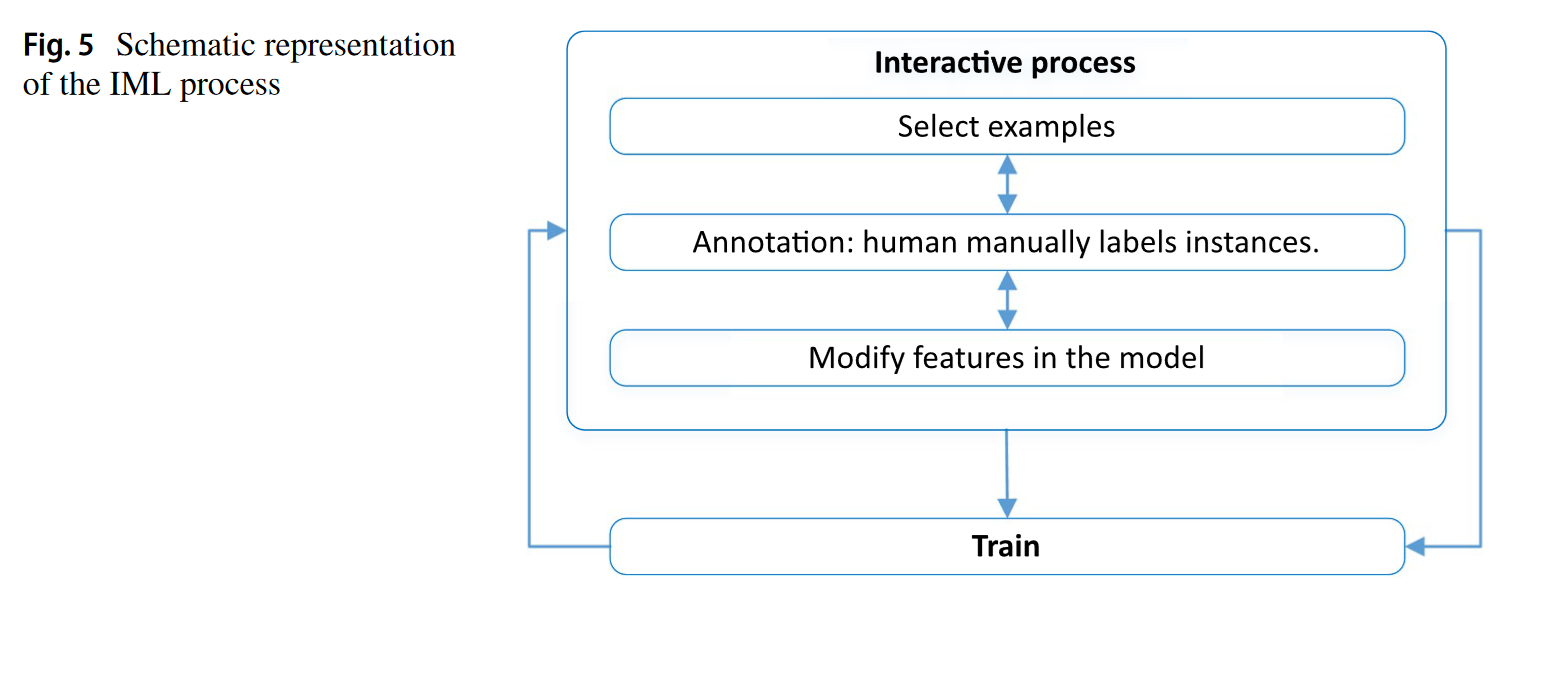
Source: A Survey of Deep Active Learning
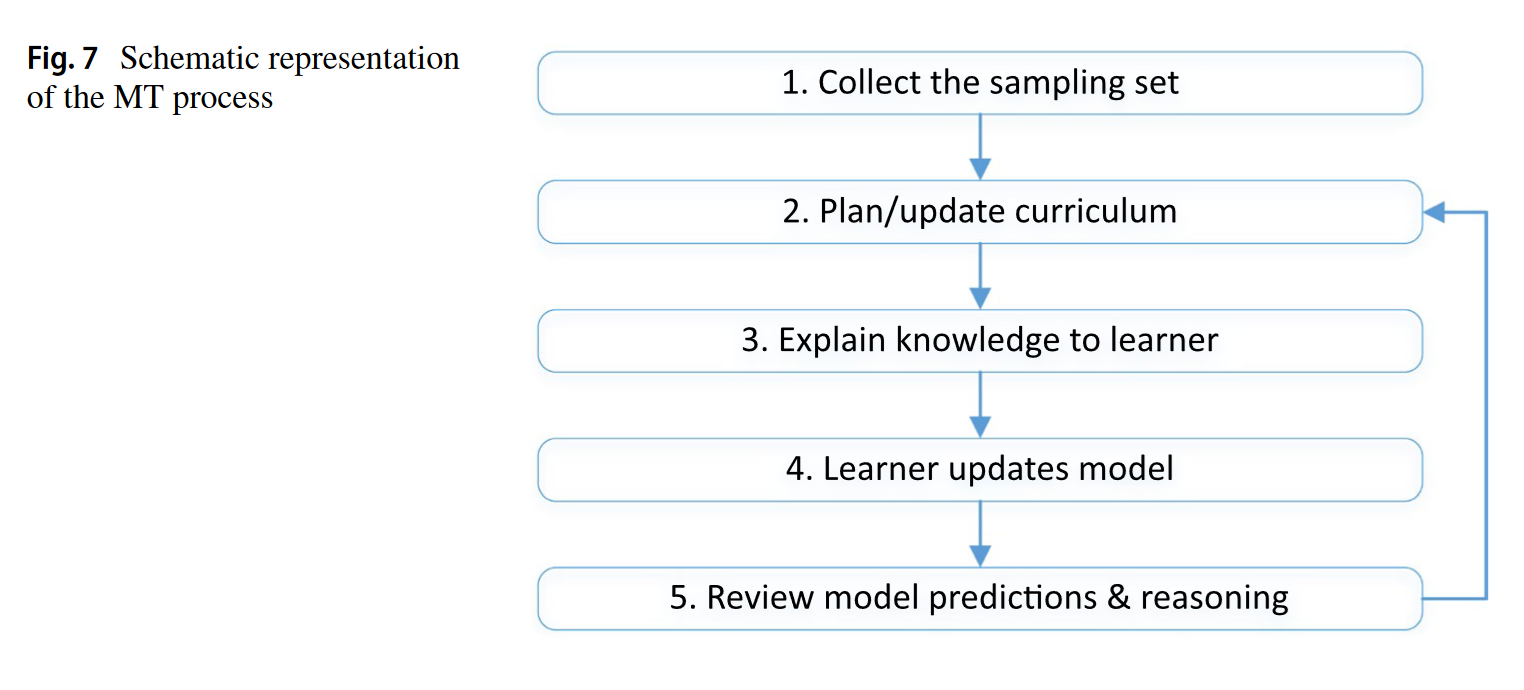
Machine Teaching (MT) gives the human (or another AI system) the role of a “teacher.” It controls which examples are shown, how they are labeled, and can even modify the features. This allows more precise guidance of the learning process, such as in systems like SOLOIST where users correct the model’s responses in real time.
Source: A Survey of Deep Active Learning