Affective computing : reconnaissance d’émotions non conventionnelles
Dans le cadre de ma formation, j’ai eu l’opportunité de participé à des projets innovants tels que celui-ci. Ce projet avait pour but d’explorer les solutions possible pour implémenter une solution d’apprentissage incrémentale et d’apprentissage active pour la reconnaissance d’émotions (CFEE, Compound Facial Expressions of Emotion)
Ce projet a été proposé par le laboratoire de recherche “Learning Data Robotics” (LDR) de l’ESIEA. L’encadrement est assuré par Lionel Prevost, Professeur des Universités, directeur du laboratoire LDR (Learning, Data & Robotics) et Khadija Slimani, Docteure, membre du LDR.
La reconnaissance d’émotions est une problématique bien connue de l’intelligence artificielle, l’affective computing a pour objectif d’analyser les états émotionels humaines en s’appuyant sur des données vidéos qui permettent de déterminer l’état émotionnel avec des traits non verbal, paraverbal et verbal.
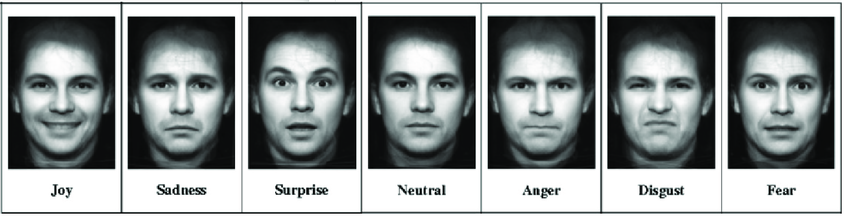
L’état de l’art dans ce domaine se concentre principalement sur les émotions basiques (la peur, la colère, la joie, la surprise, la tristesse et le dégout définies par Ekman). Cependant, dans de nombreux contextes, les individus expriment rarement ces type d’émotions et exprime des émotions dites complexes telles que la confiance ou la fierté. De plus l’interprétation de ces émotions ne sont pas universelle. Le but de notre projet est d’améliorer la classification en ajoutant au modèle les émotions au fur et à mesure de l’apprentissage.
Le laboratoire explore des solutions de reconnaissance d’émotion dans ces contextes en particulier:
Les interactions pédagogiques en vue de créer un système tutoriel intelligent et affectif, capable d’accompagner au mieux l’étudiant dans ses apprentissages ;
La prise de parole en public (soutenance, entretien de recrutement) pour aider l’individu à contrôler sa communication non verbale
Les objectifs du projet sont :
Réaliser un état de l’art sur l’apprentissage incrémental ;
Développer un outil d’annotation semi-automatique ;
Développer des modèles incrémentaux en classes et en données.
L’une des premières tâches à effectuer avant d’explorer les différentes pistes possibles est l’élaboration d’un état de l’art. Explication des différents termes qui ont été explorés pour l’écriture de l’état de l’art.
Etat de l’art
Un état de l’art consiste à effectuer une revue exhaustive des travaux existants sur un sujet donné, afin de comprendre les avancées, les lacunes et les tendances actuelles dans un domaine. L’état de l’art permet de situer le projet dans son contexte scientifique et technique, et d’identifier les opportunités d’innovation.
Dans notre cas, nous avons rédigé un état de l’art centré sur l’apprentissage incrémental (Incremental Learning) et l’apprentissage actif (Active Learning). D’autres concepts peuvent être abordés s’ils sont en lien ou pertinents avec ces sujets.
Apprentissage incrémental (IL)
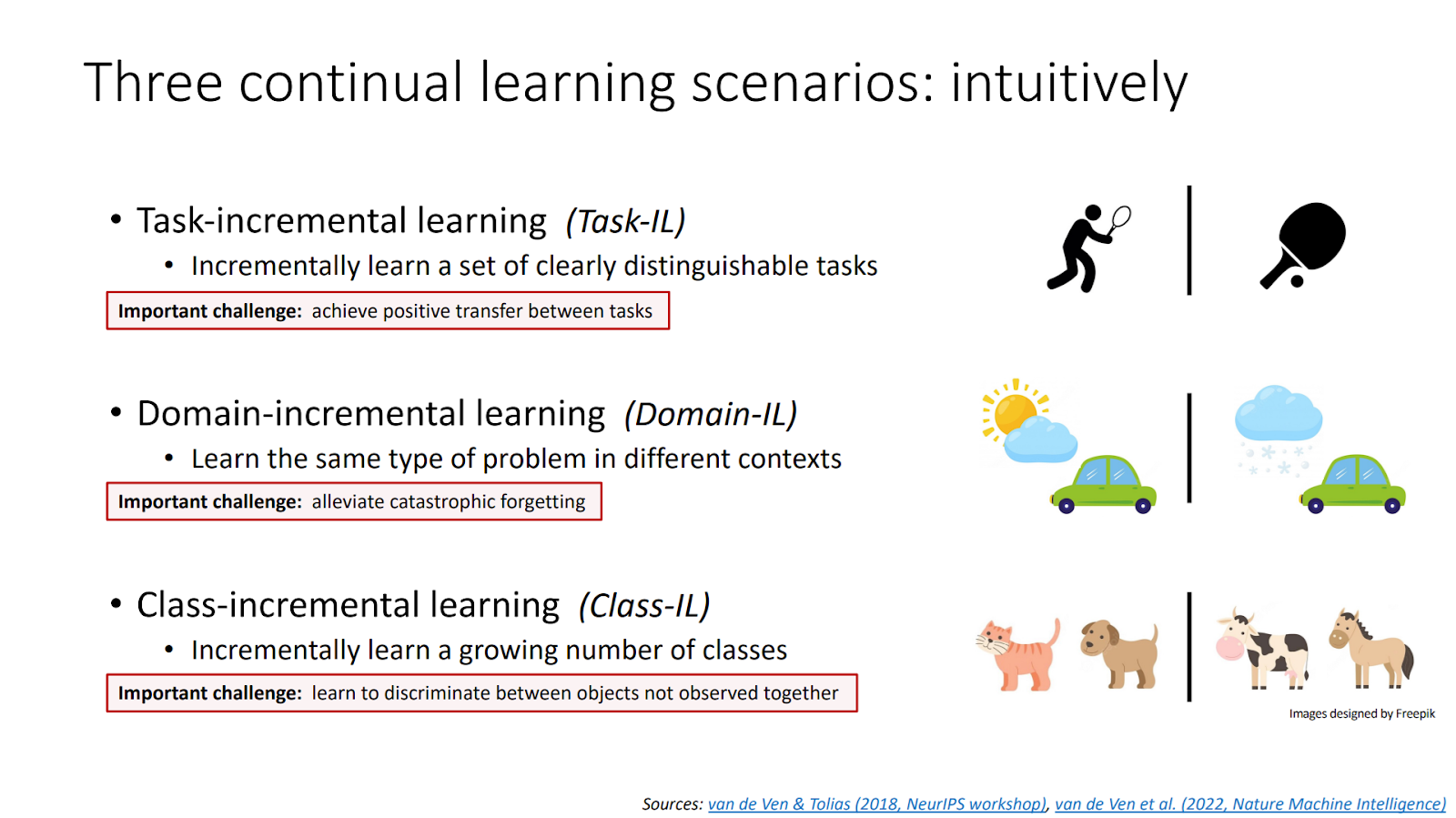
L’apprentissage incrémental (IL) permet à un modèle d’apprendre continuellement de nouvelles données sans devoir tout réentraîner. Contrairement au machine learning classique, l’IL met à jour ses connaissances sans oublier les anciennes. Il existe trois formes : par tâche (Task-IL), par domaine (Domain-IL) et par classe (Class-IL), chacune adaptée à un contexte particulier d’évolution des données.
Les difficultés de l’apprentissage incrémental (IL) et les solutions
L’oubli catastrophique est le principal défi de l’IL : les nouveaux apprentissages écrasent souvent les anciens. Des techniques comme l’adaptation des forêts aléatoires ou l’usage de classificateurs spécifiques comme Nearest Class Mean peuvent aider à atténuer ce problème, en combinant efficacité mémoire et robustesse.
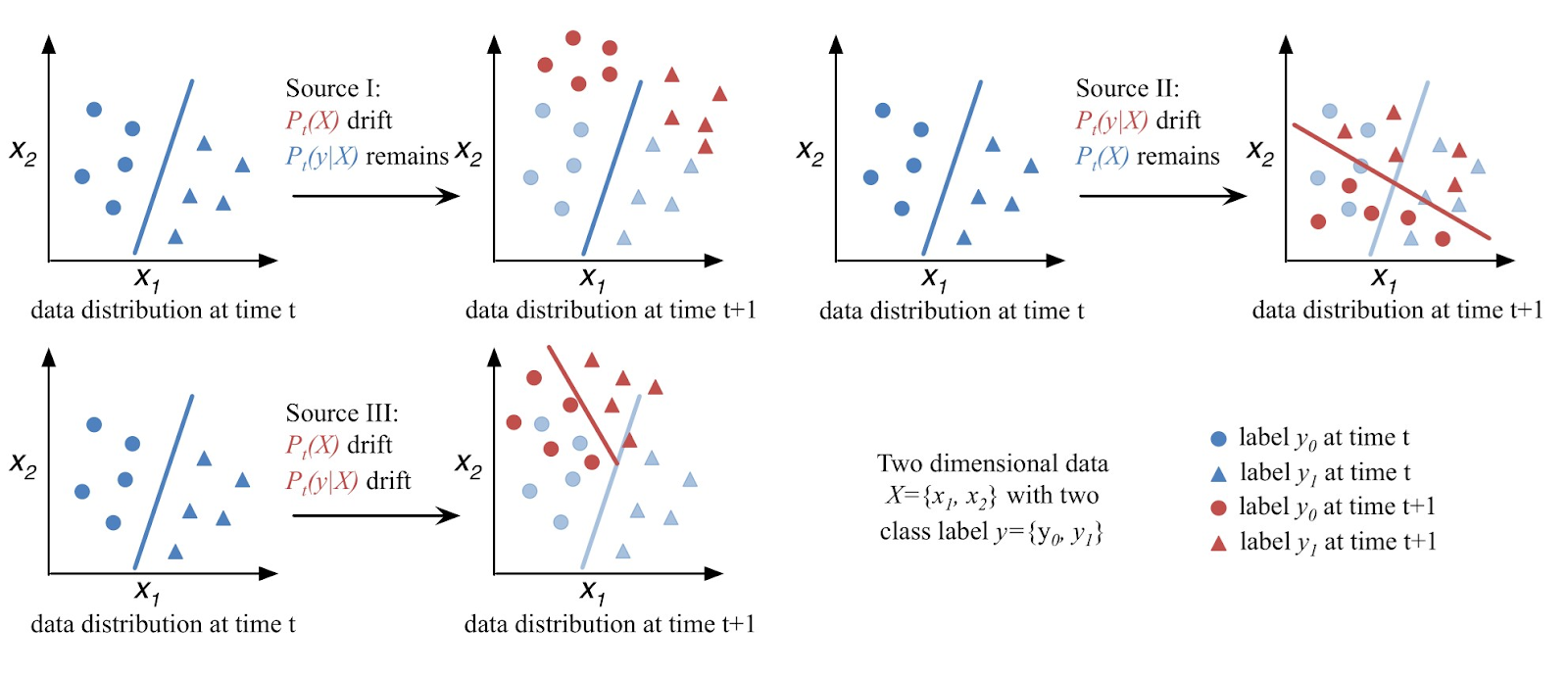
La dérive conceptuelle (Concept Drift) désigne l’évolution dans le temps des distributions de données. Cela nuit aux performances du modèle si non détecté. On distingue la dérive virtuelle, réelle ou complète, avec différents types (soudaines, progressives, récurrentes). Des méthodes comme DDM, LSDD ou HCDT permettent de la détecter via le suivi d’erreurs ou de distributions.
Les techniques de rehearsal et pseudo-rehearsal visent à contrer l’oubli. Le rehearsal stocke quelques anciens exemples en mémoire. Le pseudo-rehearsal génère des données artificielles similaires grâce à des générateurs. iCaRL combine ces méthodes avec de la distillation pour préserver les connaissances anciennes tout en apprenant de nouvelles classes.
Apprentissage actif (Active Learning)
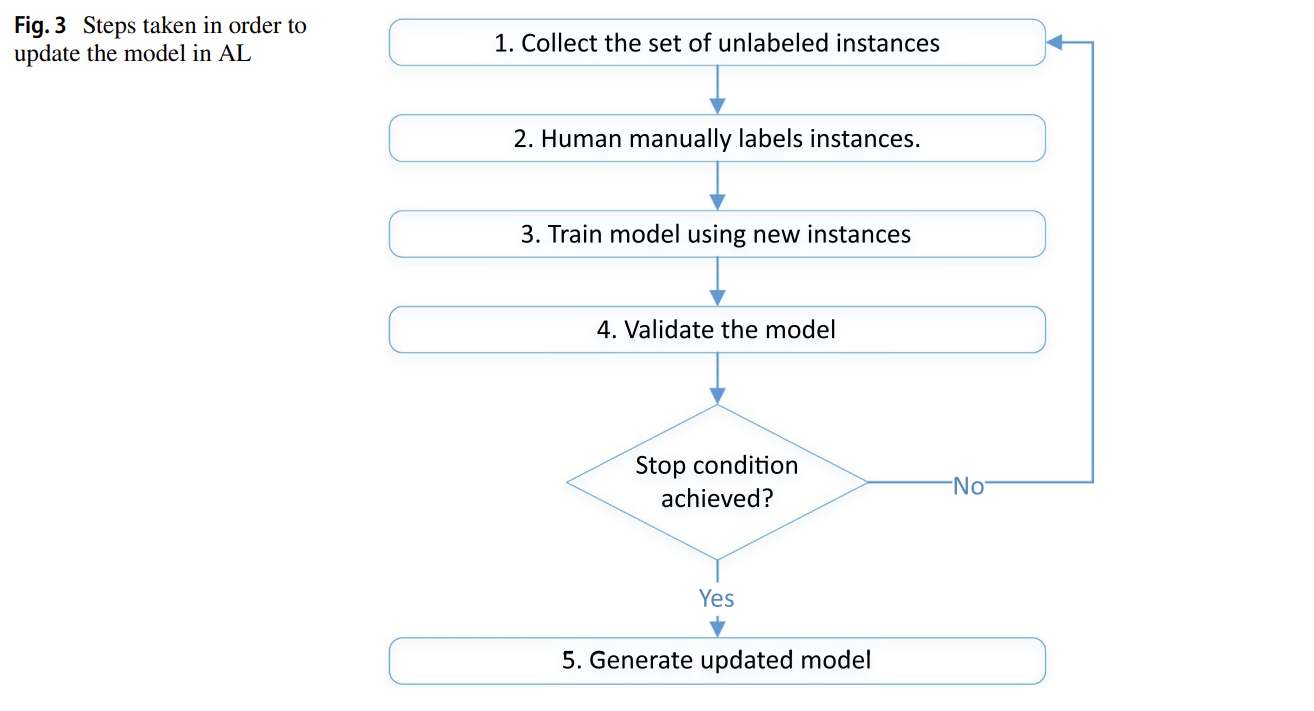
L’Active Learning (AL) implique l’humain dans le processus : le modèle sélectionne les exemples les plus informatifs à faire labelliser. Cela permet de maximiser l’apprentissage tout en minimisant l’effort de labellisation. Trois stratégies sont utilisées : aléatoire, incertitude (données ambiguës), ou diversité (exemples variés et représentatifs).
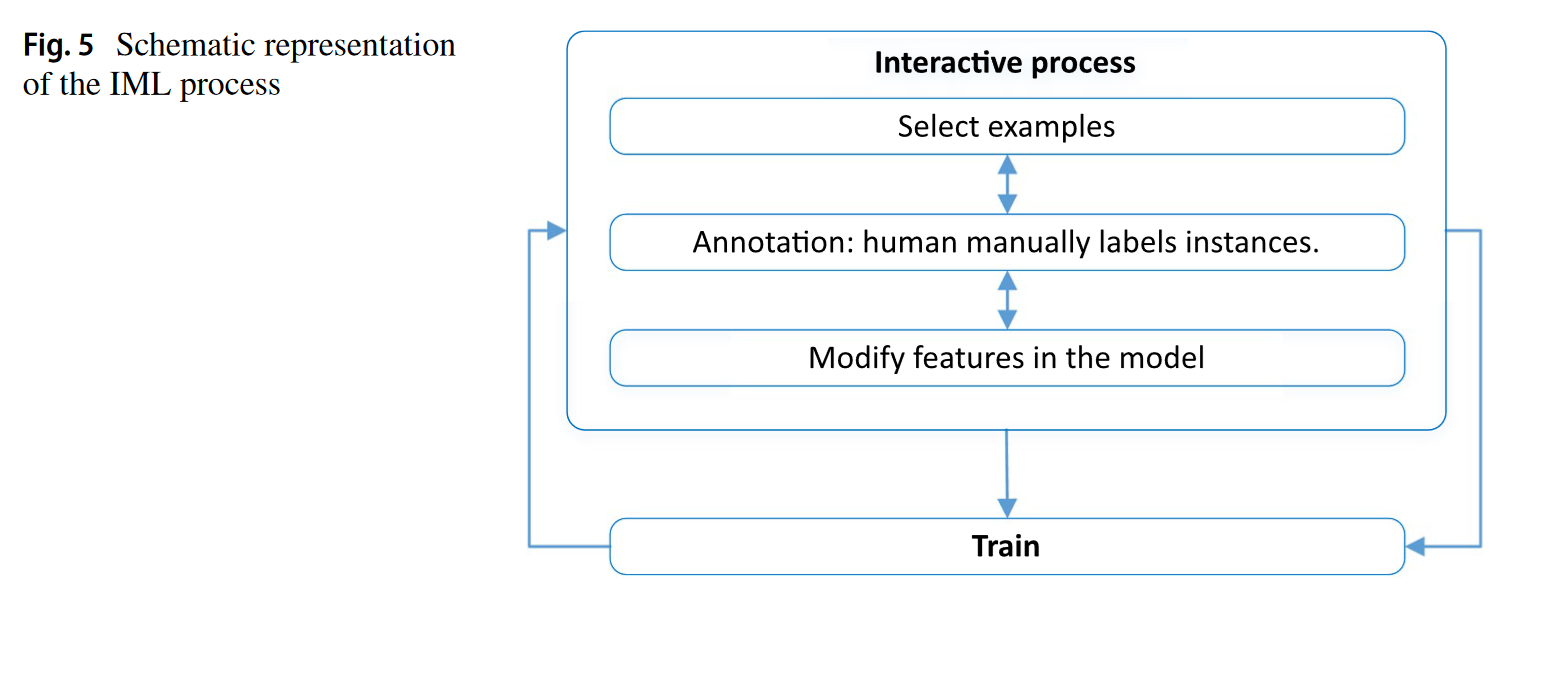
L’Interactive Machine Learning (IML) pousse plus loin l’AL : l’humain n’est pas qu’un oracle, il peut aussi choisir quelles données annoter ou corriger le modèle pendant l’apprentissage. C’est utile lorsque peu de données sont labellisées, ou quand l’automatisation seule ne suffit pas. Cela rend l’IA plus accessible à des non-experts.
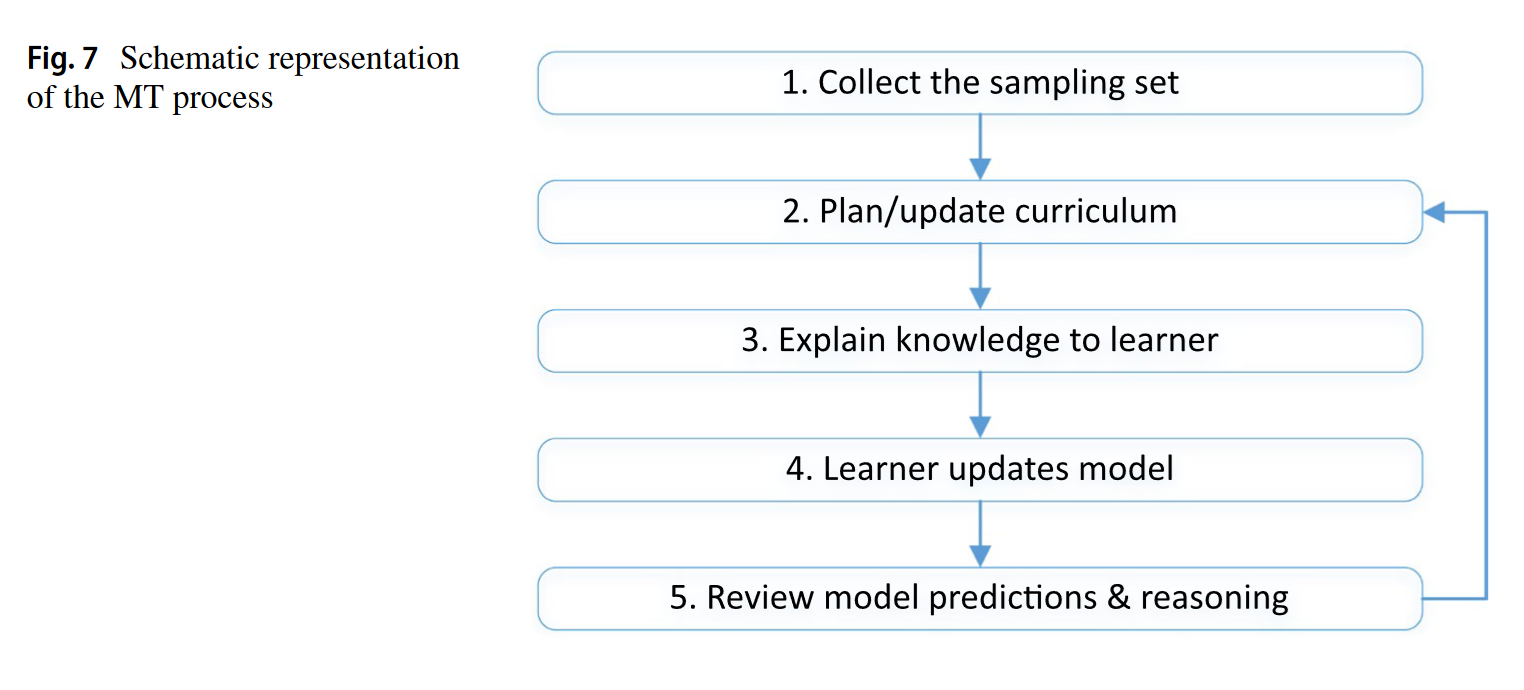
Le Machine Teaching (MT) donne à l’humain (ou une IA) le rôle de “professeur”. Il contrôle quels exemples sont vus, comment ils sont étiquetés, et peut même modifier les features si nécessaire. Cela permet de guider plus précisément l’apprentissage, par exemple dans les systèmes de dialogue comme SOLOIST, où l’utilisateur peut corriger les réponses du modèle.
Cette partie est dédiée aux différentes explorations et idées que nous avons élaborées pour implémenter une solution incrémentale pour la reconnaissance d’émotions.
Exploration et recherche
Ayant réalisé l’état de l’art, nous avons identifié plusieurs pistes d’exploration, telles que l’implémentation d’un modèle iCaRL ou d’autres architectures adaptées à l’apprentissage incrémental. Par ailleurs, la base de données CFEE (Compound Facial Expressions of Emotion) a été utilisée pour notre projet, constituant un socle pertinent pour l’entraînement et l’évaluation de nos modèles.
CFEE (Compound Facial Expressions of Emotion)
La base de données CFEE est composée d’images d’émotions actées par des volontaires. Cela implique un biais possible, car les émotions ne sont pas spontanées. Elle contient 22 émotions : les 6 émotions de base d’Ekman, l’émotion neutre, ainsi que 15 émotions complexes, telles que Happily_Disgusted ou Sadly_Surprised, qui sont des combinaisons d’émotions basiques.
Cette base est utilisée pour entraîner et tester nos modèles de reconnaissance d’émotions de manière incrémentale.
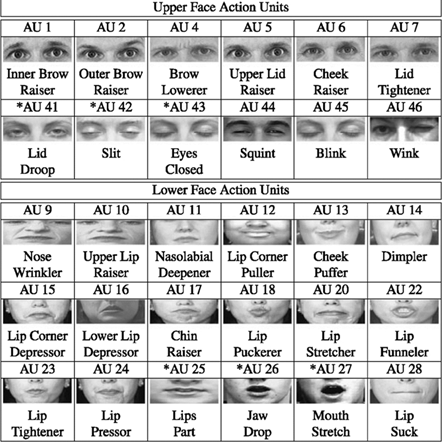
Action Unit (AU)
Les Action Units (AU) sont des mesures d’activation des muscles du visage. Elles peuvent être binaires (activées ou non) ou exprimées en intensité. Les AU sont extraites automatiquement à l’aide de l’outil OpenFace. Elles ont l’avantage d’être interprétables, compactes, et adaptées aux modèles incrémentaux grâce à leur faible dimension.
Le modèle iCaRL a été mentionné dans notre état de l’art comme une référence en apprentissage incrémental par classes. Nous avons exploré son potentiel pour notre cas d’usage. Cependant, son implémentation nécessite la gestion complexe d’un ensemble d’exemples mémorisés, la distillation des connaissances et une architecture personnalisée. En raison de ces contraintes, iCaRL n’a pas été retenu dans notre pipeline expérimental, au profit de solutions plus simples et compatibles avec notre environnement.
Autoencoder
Les autoencodeurs sont des réseaux de neurones non supervisés capables de compresser et de reconstruire des données. Nous avons envisagé leur utilisation pour extraire des features compactes à partir des images, ou encore pour générer des données synthétiques (pseudo-rehearsal). Cette approche permet de réduire les besoins en stockage tout en préservant des représentations utiles pour la classification incrémentale.
Batching
Dans le cadre de notre projet, le batching désigne le découpage du jeu de données en lots successifs de classes. Ce mécanisme permet de simuler un scénario d’apprentissage incrémental par classes, où les données de nouvelles classes sont introduites au modèle de manière progressive, sans accès aux anciennes.
Deux stratégies ont été envisagées :
Un batch groupé contenant d’abord les émotions de base, suivi de batches ajoutant progressivement les émotions composées par groupes.
Un batch unitaire, dans lequel chaque nouvelle classe d’émotion est introduite individuellement, simulant un apprentissage encore plus fin et contrôlé.
Cette approche nous permet de :
Évaluer la robustesse du modèle face à l’oubli catastrophique.
Mesurer l’impact de chaque classe ajoutée sur les performances globales.
Tester des techniques comme le rehearsal ou l’active learning dans un cadre contrôlé.
Modèles incrémentaux existants
Nous avons testé plusieurs modèles incrémentaux disponibles dans la bibliothèque scikit-learn, tels que :
Multinomial Naive Bayes (MNB)
Perceptron (SGDClassifier)
Passive-Aggressive Classifier (PAC)
Bernoulli Naive Bayes (BNB)
Random Forests, adaptées en mode batch
MLPClassifier, utilisé avec une mise à jour incrémentale contrôlée
Ces modèles ont servi de baseline, permettant une évaluation rapide des performances en mode incrémental, notamment à partir des AU et des vecteurs de features issus de CNN.
3 - Implémentation
L’implémentation expérimentale finale repose sur l’utilisation de modèles incrémentaux existants dans la bibliothèque scikit-learn. Ces modèles exploitent les Action Units (AU) extraits des images de la base CFEE, ainsi que des vecteurs de caractéristiques issus de modèles pré-entraînés.
Implémentation
Nous avons tout d’abord comparé plusieurs modèles non incrémentaux afin d’établir une baseline de performance. Le modèle le plus performant sur l’ensemble des 22 émotions est une Random Forest, atteignant un score de 0.69. Cette étape a permis de situer les modèles incrémentaux dans notre contexte. Comme indiqué précédemment, nous utilisons la base de données CFEE, et extrayons les Action Units (AU) via l’outil OpenFace.
En complément des AU, nous avons extrait des features avancées à l’aide de modèles pré-entraînés tels que GoogleNet, ResNet et MobileNet. Ces vecteurs de caractéristiques enrichissent les entrées des modèles de classification, en leur fournissant une représentation visuelle plus complexe que les AU seuls.
Modèles incrémentaux
Pour l’apprentissage incrémental, nous avons utilisé des modèles disponibles dans scikit-learn, compatibles avec l’ajout de données par batch, notamment :
Random Forest (adapté via partial_fit)
Perceptron (SGDClassifier)
Bernoulli Naive Bayes (BNB)
Multinomial Naive Bayes (MNB)
MLPClassifier (mise à jour itérative)
Passive-Aggressive Classifier (PAC)
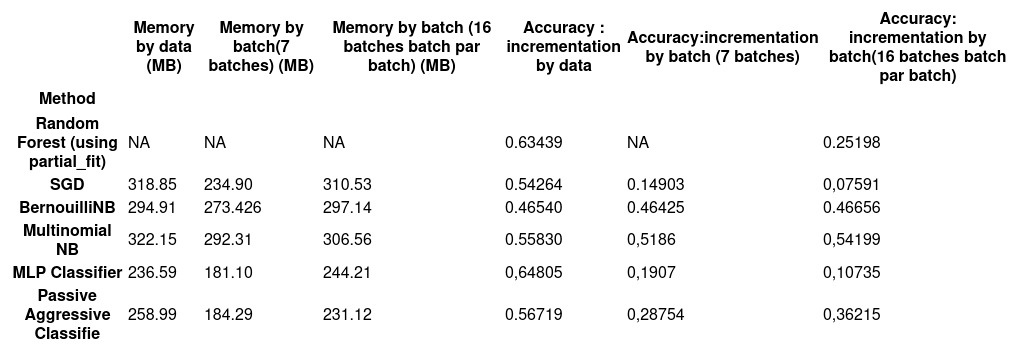
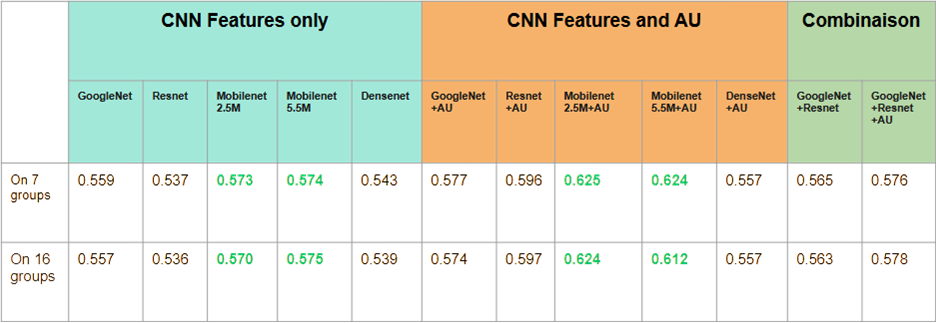
Les performances des différents modèles utilisant uniquement les AU sont présentées ci-dessous :
Ces modèles ont ensuite été testés avec une entrée enrichie : AU + features CNN, afin de mesurer l’impact de cette combinaison sur les performances.
Modèles pré-entraînés
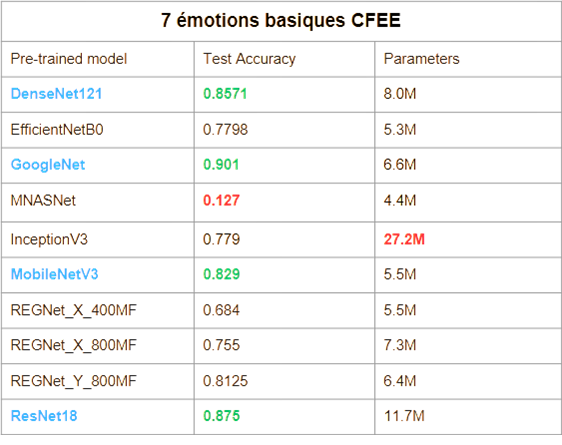
Nous avons évalué plusieurs modèles de type CNN pré-entraînés sur ImageNet, appliqués aux 7 émotions de base (6 émotions d’Ekman + neutre). Cette restriction est imposée par la nature de l’apprentissage incrémental, qui empêche le modèle d’avoir accès à l’ensemble des classes dès le départ.
Le but est d’utiliser ces CNN uniquement comme extracteurs de features, sans leurs couches de classification finales.
Les modèles les plus performants sont :
DenseNet121
GoogleNet
MobileNet v3
ResNet-18
Ces réseaux sont utilisés pour transformer les images CFEE en vecteurs de caractéristiques, en retirant leur dernière couche. Les vecteurs obtenus sont ensuite concaténés avec les AU afin de servir d’entrée aux modèles incrémentaux.
Implémentation finale
L’approche retenue repose sur l’utilisation combinée des Action Units et des features CNN, avec comme classifieur final le Multinomial Naive Bayes (MNB), qui a obtenu les meilleurs résultats dans nos expérimentations incrémentales.
Cette architecture présente un bon compromis entre précision, faible complexité, efficacité mémoire, et compatibilité avec un apprentissage incrémental classe-par-classe.
Les performances finales du modèle MNB selon les types de features sont présentées ci-dessous :
Conclusion et perspectives
Notre approche basée sur l’apprentissage incrémental a permis de traiter efficacement la reconnaissance d’émotions à partir de la base de données CFEE, en combinant des Action Units extraits par OpenFace et des features visuelles issues de CNN pré-entraînés. Le classifieur Multinomial Naive Bayes s’est distingué comme la solution la plus adaptée à notre configuration, avec un bon équilibre entre performance, simplicité et capacité d’incrémentation.
Cependant, plusieurs limites ont été observées :
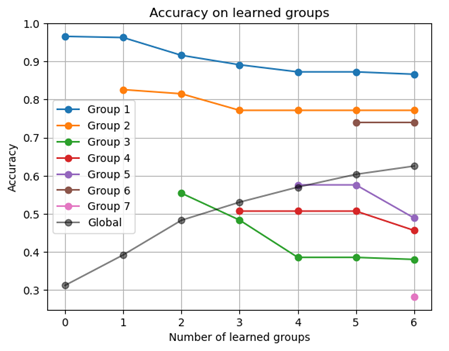
Un oubli catastrophique d’environ 10 % sur les émotions de base.
Des groupes spécifiques (3, 4, 5, 7) difficiles à distinguer, probablement en raison de features peu discriminantes.
Une confusion importante entre certaines émotions composites, nécessitant une meilleure séparation des classes.
Ces constats ouvrent des pistes de perspectives intéressantes pour de futurs travaux :
Développer une méthode de séparation plus fine des classes confondues, via une exploration plus approfondie des représentations latentes.
Adapter dynamiquement l’architecture du CNN extracteur de features à mesure que de nouveaux batches sont introduits.
Mettre en place un mécanisme de rehearsal intelligent, en sélectionnant automatiquement les exemples les plus significatifs.
Expérimenter avec des modèles génératifs (ex. : GANs, VAE) pour mettre en œuvre une stratégie de pseudo-rehearsal, limitant la perte de mémoire sans stocker de vraies données.