Exploration et recherche
Exploration et recherche
Ayant réalisé l’état de l’art, nous avons identifié plusieurs pistes d’exploration, telles que l’implémentation d’un modèle iCaRL ou d’autres architectures adaptées à l’apprentissage incrémental. Par ailleurs, la base de données CFEE (Compound Facial Expressions of Emotion) a été utilisée pour notre projet, constituant un socle pertinent pour l’entraînement et l’évaluation de nos modèles.
CFEE (Compound Facial Expressions of Emotion)
La base de données CFEE est composée d’images d’émotions actées par des volontaires. Cela implique un biais possible, car les émotions ne sont pas spontanées. Elle contient 22 émotions : les 6 émotions de base d’Ekman, l’émotion neutre, ainsi que 15 émotions complexes, telles que Happily_Disgusted ou Sadly_Surprised, qui sont des combinaisons d’émotions basiques.

Source : Compound Facial Expression Recognition Based on Highway CNN
Cette base est utilisée pour entraîner et tester nos modèles de reconnaissance d’émotions de manière incrémentale.
Action Unit (AU)
Les Action Units (AU) sont des mesures d’activation des muscles du visage. Elles peuvent être binaires (activées ou non) ou exprimées en intensité. Les AU sont extraites automatiquement à l’aide de l’outil OpenFace. Elles ont l’avantage d’être interprétables, compactes, et adaptées aux modèles incrémentaux grâce à leur faible dimension.
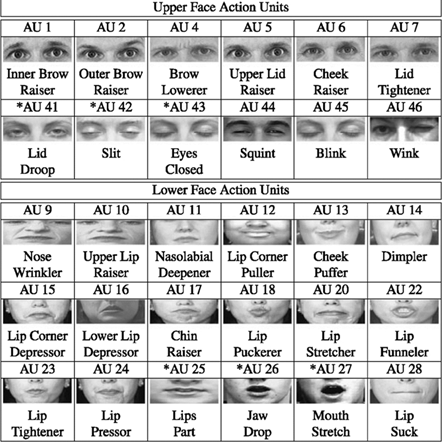
Source : A comprehensive survey on automatic facial action unit analysis
iCaRL
Le modèle iCaRL a été mentionné dans notre état de l’art comme une référence en apprentissage incrémental par classes. Nous avons exploré son potentiel pour notre cas d’usage. Cependant, son implémentation nécessite la gestion complexe d’un ensemble d’exemples mémorisés, la distillation des connaissances et une architecture personnalisée. En raison de ces contraintes, iCaRL n’a pas été retenu dans notre pipeline expérimental, au profit de solutions plus simples et compatibles avec notre environnement.
Autoencoder
Les autoencodeurs sont des réseaux de neurones non supervisés capables de compresser et de reconstruire des données. Nous avons envisagé leur utilisation pour extraire des features compactes à partir des images, ou encore pour générer des données synthétiques (pseudo-rehearsal). Cette approche permet de réduire les besoins en stockage tout en préservant des représentations utiles pour la classification incrémentale.
Batching
Dans le cadre de notre projet, le batching désigne le découpage du jeu de données en lots successifs de classes. Ce mécanisme permet de simuler un scénario d’apprentissage incrémental par classes, où les données de nouvelles classes sont introduites au modèle de manière progressive, sans accès aux anciennes.
Deux stratégies ont été envisagées :
- Un batch groupé contenant d’abord les émotions de base, suivi de batches ajoutant progressivement les émotions composées par groupes.
- Un batch unitaire, dans lequel chaque nouvelle classe d’émotion est introduite individuellement, simulant un apprentissage encore plus fin et contrôlé.
Cette approche nous permet de :
- Évaluer la robustesse du modèle face à l’oubli catastrophique.
- Mesurer l’impact de chaque classe ajoutée sur les performances globales.
- Tester des techniques comme le rehearsal ou l’active learning dans un cadre contrôlé.

Modèles incrémentaux existants
Nous avons testé plusieurs modèles incrémentaux disponibles dans la bibliothèque scikit-learn, tels que :
- Multinomial Naive Bayes (MNB)
- Perceptron (SGDClassifier)
- Passive-Aggressive Classifier (PAC)
- Bernoulli Naive Bayes (BNB)
- Random Forests, adaptées en mode batch
- MLPClassifier, utilisé avec une mise à jour incrémentale contrôlée
Ces modèles ont servi de baseline, permettant une évaluation rapide des performances en mode incrémental, notamment à partir des AU et des vecteurs de features issus de CNN.