L’implémentation expérimentale finale repose sur l’utilisation de modèles incrémentaux existants dans la bibliothèque scikit-learn. Ces modèles exploitent les Action Units (AU) extraits des images de la base CFEE, ainsi que des vecteurs de caractéristiques issus de modèles pré-entraînés.
Implémentation
Nous avons tout d’abord comparé plusieurs modèles non incrémentaux afin d’établir une baseline de performance. Le modèle le plus performant sur l’ensemble des 22 émotions est une Random Forest, atteignant un score de 0.69. Cette étape a permis de situer les modèles incrémentaux dans notre contexte. Comme indiqué précédemment, nous utilisons la base de données CFEE, et extrayons les Action Units (AU) via l’outil OpenFace.
En complément des AU, nous avons extrait des features avancées à l’aide de modèles pré-entraînés tels que GoogleNet, ResNet et MobileNet. Ces vecteurs de caractéristiques enrichissent les entrées des modèles de classification, en leur fournissant une représentation visuelle plus complexe que les AU seuls.
Modèles incrémentaux
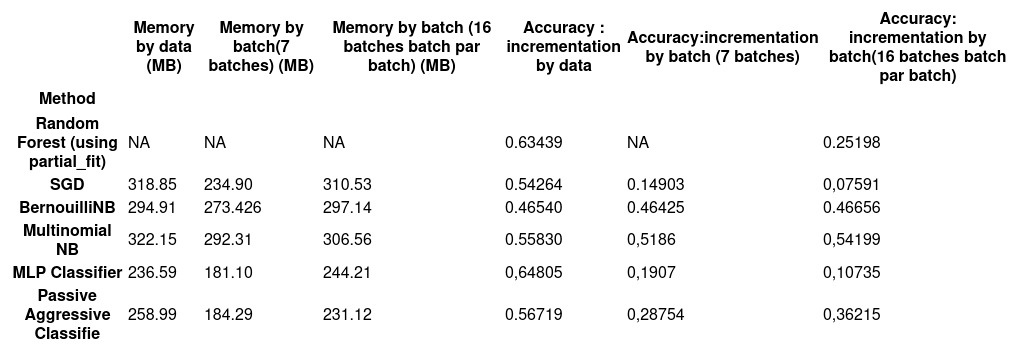
Pour l’apprentissage incrémental, nous avons utilisé des modèles disponibles dans scikit-learn, compatibles avec l’ajout de données par batch, notamment :
Random Forest (adapté via partial_fit)
Perceptron (SGDClassifier)
Bernoulli Naive Bayes (BNB)
Multinomial Naive Bayes (MNB)
MLPClassifier (mise à jour itérative)
Passive-Aggressive Classifier (PAC)
Les performances des différents modèles utilisant uniquement les AU sont présentées ci-dessous :
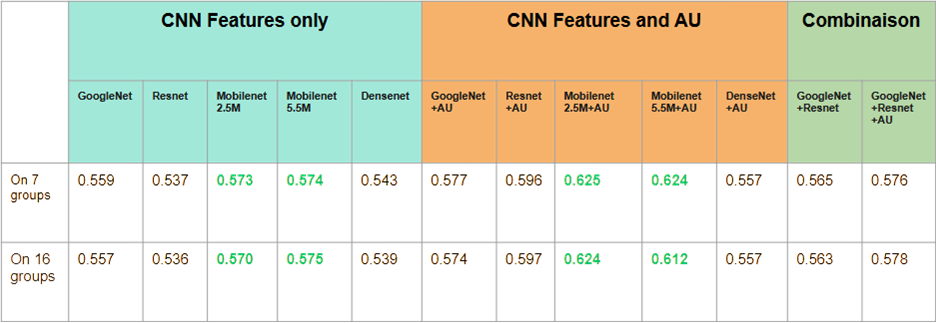
Ces modèles ont ensuite été testés avec une entrée enrichie : AU + features CNN, afin de mesurer l’impact de cette combinaison sur les performances.
Modèles pré-entraînés
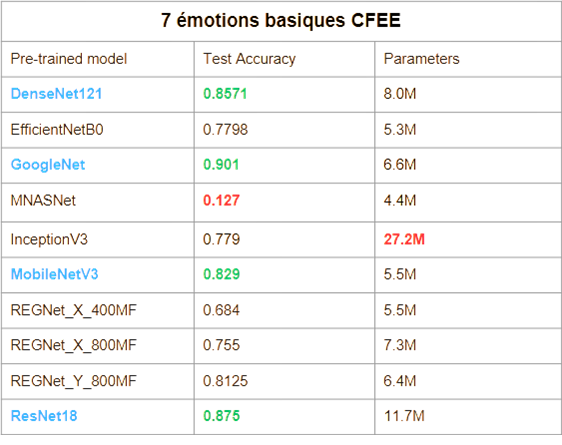
Nous avons évalué plusieurs modèles de type CNN pré-entraînés sur ImageNet, appliqués aux 7 émotions de base (6 émotions d’Ekman + neutre). Cette restriction est imposée par la nature de l’apprentissage incrémental, qui empêche le modèle d’avoir accès à l’ensemble des classes dès le départ.
Le but est d’utiliser ces CNN uniquement comme extracteurs de features, sans leurs couches de classification finales.
Les modèles les plus performants sont :
DenseNet121
GoogleNet
MobileNet v3
ResNet-18
Ces réseaux sont utilisés pour transformer les images CFEE en vecteurs de caractéristiques, en retirant leur dernière couche. Les vecteurs obtenus sont ensuite concaténés avec les AU afin de servir d’entrée aux modèles incrémentaux.
Implémentation finale
L’approche retenue repose sur l’utilisation combinée des Action Units et des features CNN, avec comme classifieur final le Multinomial Naive Bayes (MNB), qui a obtenu les meilleurs résultats dans nos expérimentations incrémentales.
Cette architecture présente un bon compromis entre précision, faible complexité, efficacité mémoire, et compatibilité avec un apprentissage incrémental classe-par-classe.
Les performances finales du modèle MNB selon les types de features sont présentées ci-dessous :
Conclusion et perspectives
Notre approche basée sur l’apprentissage incrémental a permis de traiter efficacement la reconnaissance d’émotions à partir de la base de données CFEE, en combinant des Action Units extraits par OpenFace et des features visuelles issues de CNN pré-entraînés. Le classifieur Multinomial Naive Bayes s’est distingué comme la solution la plus adaptée à notre configuration, avec un bon équilibre entre performance, simplicité et capacité d’incrémentation.
Cependant, plusieurs limites ont été observées :
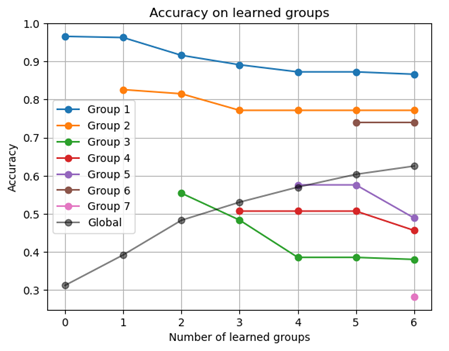
Un oubli catastrophique d’environ 10 % sur les émotions de base.
Des groupes spécifiques (3, 4, 5, 7) difficiles à distinguer, probablement en raison de features peu discriminantes.
Une confusion importante entre certaines émotions composites, nécessitant une meilleure séparation des classes.
Ces constats ouvrent des pistes de perspectives intéressantes pour de futurs travaux :
Développer une méthode de séparation plus fine des classes confondues, via une exploration plus approfondie des représentations latentes.
Adapter dynamiquement l’architecture du CNN extracteur de features à mesure que de nouveaux batches sont introduits.
Mettre en place un mécanisme de rehearsal intelligent, en sélectionnant automatiquement les exemples les plus significatifs.
Expérimenter avec des modèles génératifs (ex. : GANs, VAE) pour mettre en œuvre une stratégie de pseudo-rehearsal, limitant la perte de mémoire sans stocker de vraies données.