Etat de l'art
Etat de l’art
Un état de l’art consiste à effectuer une revue exhaustive des travaux existants sur un sujet donné, afin de comprendre les avancées, les lacunes et les tendances actuelles dans un domaine. L’état de l’art permet de situer le projet dans son contexte scientifique et technique, et d’identifier les opportunités d’innovation.
Dans notre cas, nous avons rédigé un état de l’art centré sur l’apprentissage incrémental (Incremental Learning) et l’apprentissage actif (Active Learning). D’autres concepts peuvent être abordés s’ils sont en lien ou pertinents avec ces sujets.
Apprentissage incrémental (IL)
L’apprentissage incrémental (IL) permet à un modèle d’apprendre continuellement de nouvelles données sans devoir tout réentraîner. Contrairement au machine learning classique, l’IL met à jour ses connaissances sans oublier les anciennes. Il existe trois formes : par tâche (Task-IL), par domaine (Domain-IL) et par classe (Class-IL), chacune adaptée à un contexte particulier d’évolution des données.
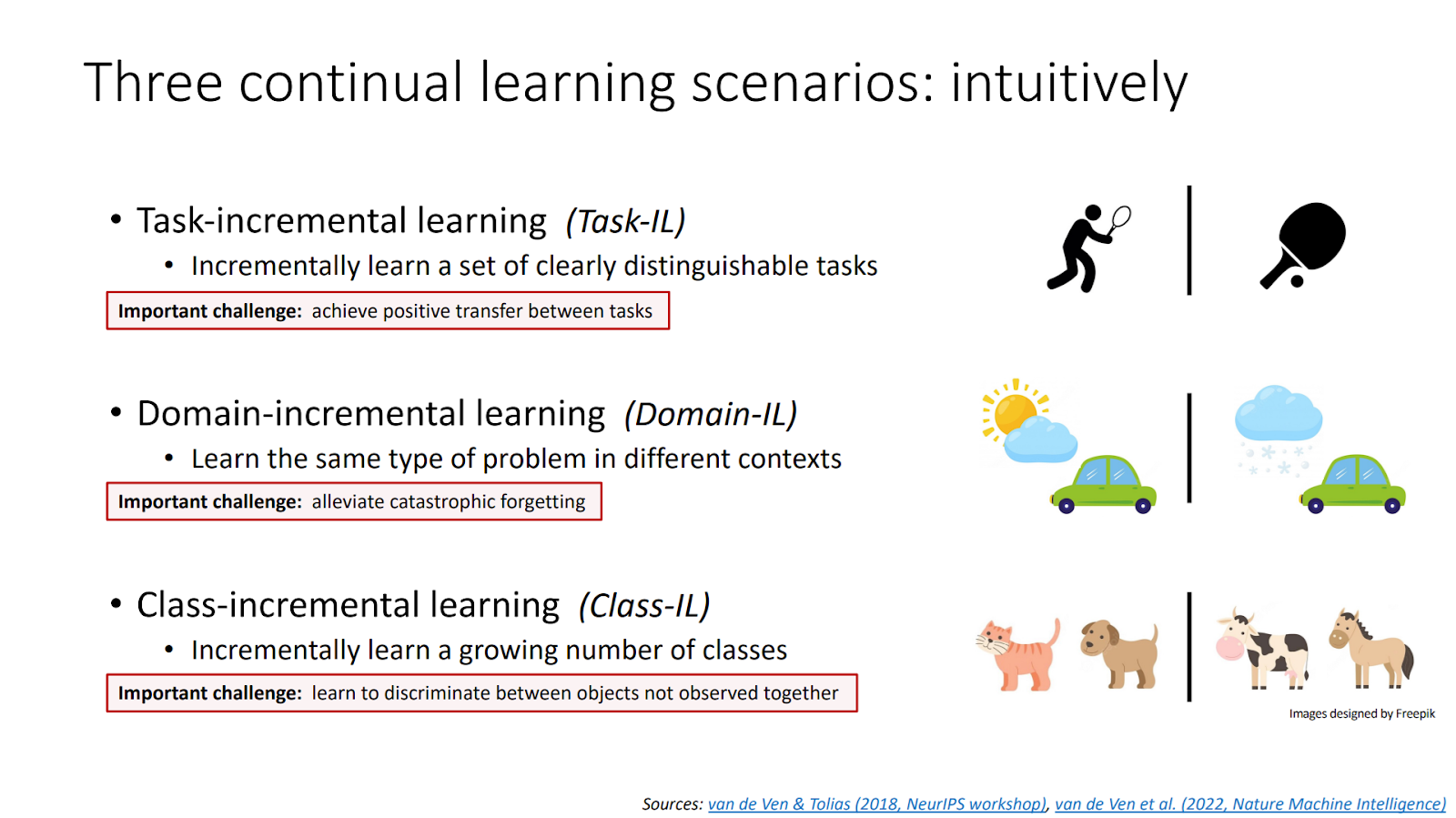
Source : Three types of incremental learning
Les difficultés de l’apprentissage incrémental (IL) et les solutions
L’oubli catastrophique est le principal défi de l’IL : les nouveaux apprentissages écrasent souvent les anciens. Des techniques comme l’adaptation des forêts aléatoires ou l’usage de classificateurs spécifiques comme Nearest Class Mean peuvent aider à atténuer ce problème, en combinant efficacité mémoire et robustesse.
La dérive conceptuelle (Concept Drift) désigne l’évolution dans le temps des distributions de données. Cela nuit aux performances du modèle si non détecté. On distingue la dérive virtuelle, réelle ou complète, avec différents types (soudaines, progressives, récurrentes). Des méthodes comme DDM, LSDD ou HCDT permettent de la détecter via le suivi d’erreurs ou de distributions.
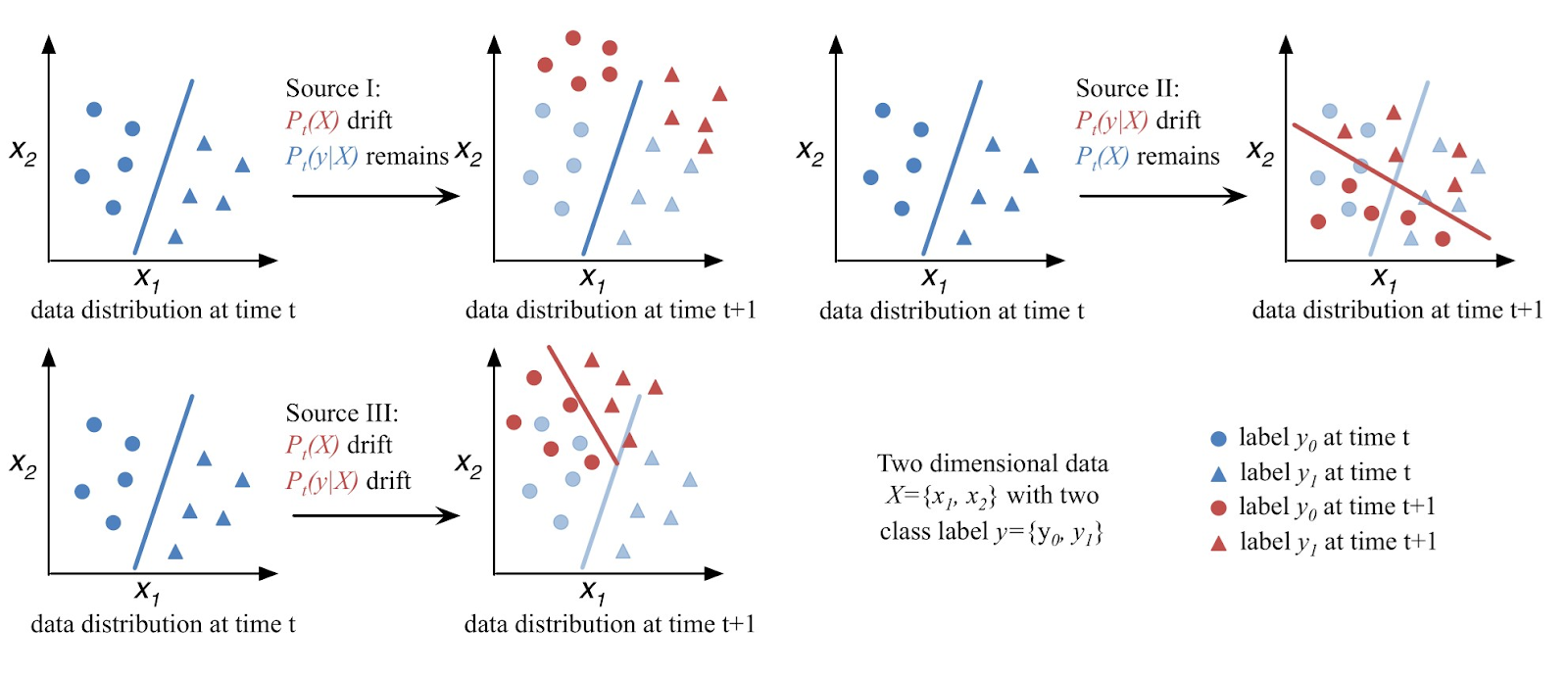
Les techniques de rehearsal et pseudo-rehearsal visent à contrer l’oubli. Le rehearsal stocke quelques anciens exemples en mémoire. Le pseudo-rehearsal génère des données artificielles similaires grâce à des générateurs. iCaRL combine ces méthodes avec de la distillation pour préserver les connaissances anciennes tout en apprenant de nouvelles classes.
Apprentissage actif (Active Learning)
L’Active Learning (AL) implique l’humain dans le processus : le modèle sélectionne les exemples les plus informatifs à faire labelliser. Cela permet de maximiser l’apprentissage tout en minimisant l’effort de labellisation. Trois stratégies sont utilisées : aléatoire, incertitude (données ambiguës), ou diversité (exemples variés et représentatifs).
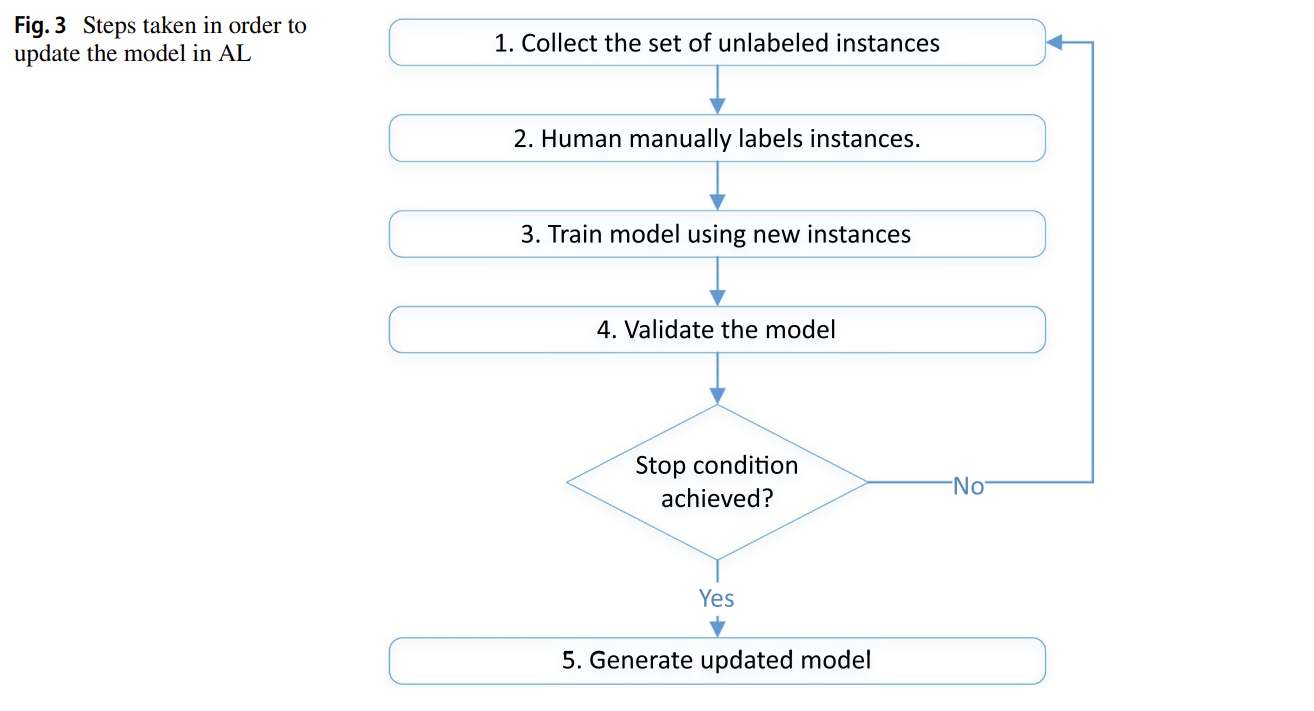
Source : A Survey of Deep Active Learning
L’Interactive Machine Learning (IML) pousse plus loin l’AL : l’humain n’est pas qu’un oracle, il peut aussi choisir quelles données annoter ou corriger le modèle pendant l’apprentissage. C’est utile lorsque peu de données sont labellisées, ou quand l’automatisation seule ne suffit pas. Cela rend l’IA plus accessible à des non-experts.
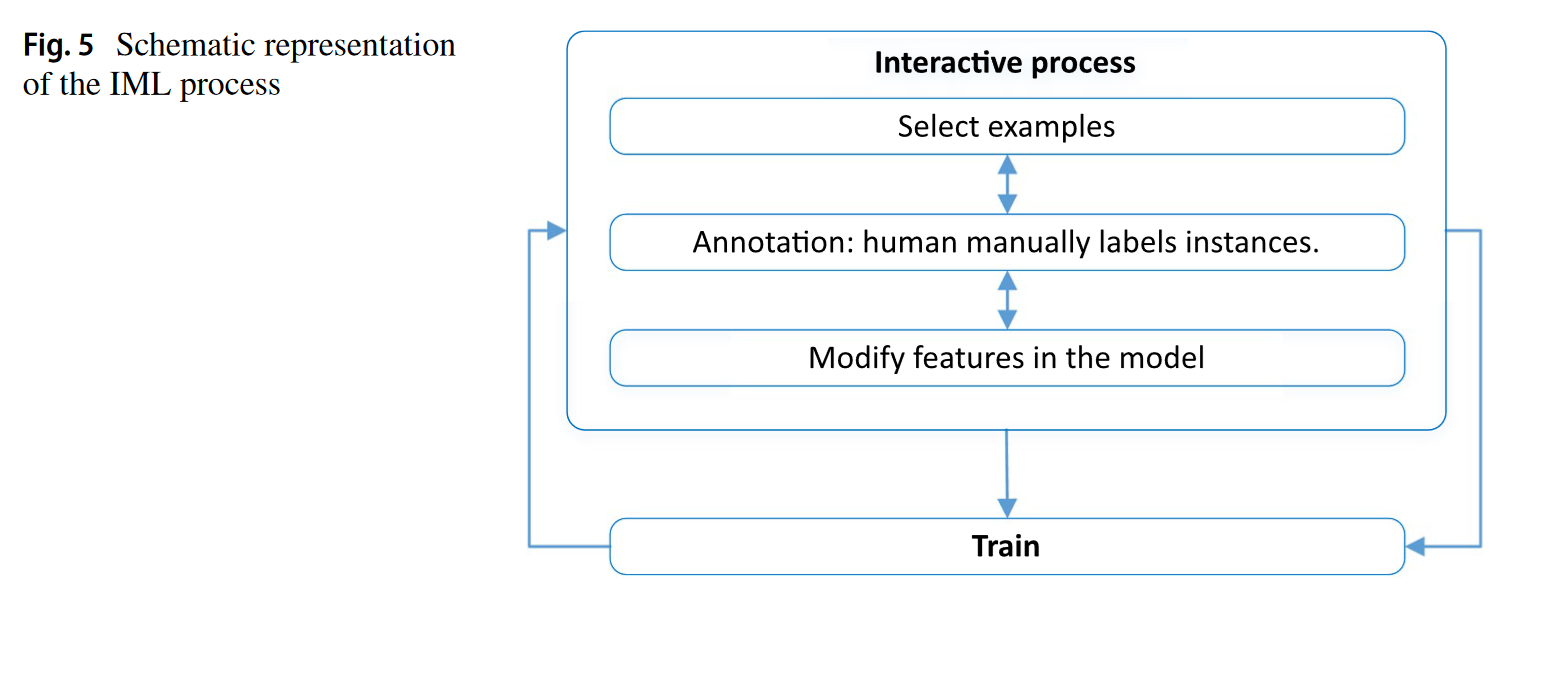
Source : A Survey of Deep Active Learning
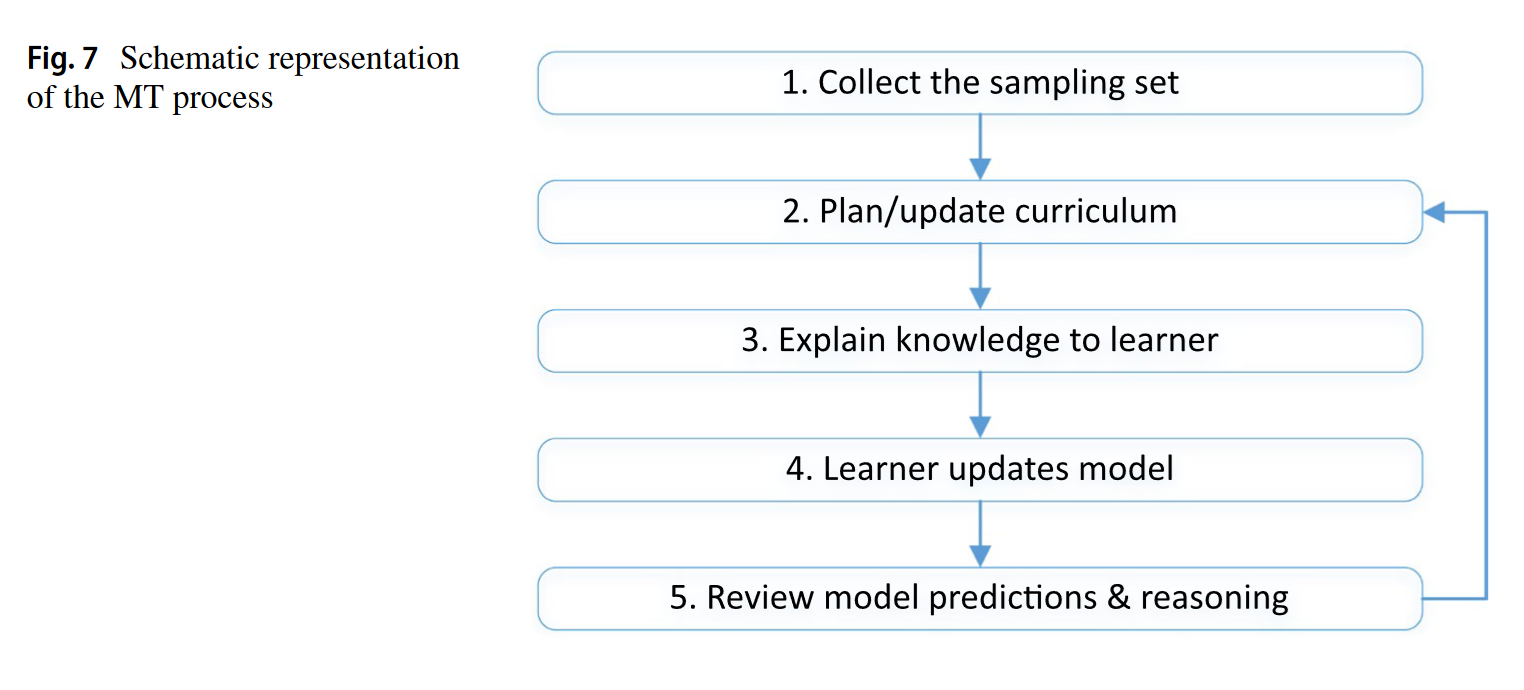
Le Machine Teaching (MT) donne à l’humain (ou une IA) le rôle de “professeur”. Il contrôle quels exemples sont vus, comment ils sont étiquetés, et peut même modifier les features si nécessaire. Cela permet de guider plus précisément l’apprentissage, par exemple dans les systèmes de dialogue comme SOLOIST, où l’utilisateur peut corriger les réponses du modèle.
Source : A Survey of Deep Active Learning