Cette page présente les différents travaux et expériences réalisés au fil du temps.
Dans cette section, vous trouverez un aperçu des expériences qui ont marqué mon parcours professionnel et personnel. Chaque expérience est décrite avec ses objectifs, les défis rencontrés et les résultats obtenus.
Ces expériences m’ont permis de développer des compétences variées et d’acquérir une expertise précieuse dans mon domaine. N’hésitez pas à me contacter pour plus d’informations ou pour discuter de futures collaborations.
1 - Stratégie d'automatisation des moyens d'analyse d'essais systèmes, MBDA
Stage technique effectué entre le 03/04/2023 et le 19/05/2023 à Le Plessis-Robinson.
Les informations en lien avec ce stage sont soumises à une politique de confidentialité. Certaines informations peuvent ne pas être divulguées.
À propos de MBDA
MBDA est une entreprise leader dans le domaine de la défense, spécialisée dans la conception et la production de systèmes de missiles. Avec une présence mondiale, MBDA développe des solutions innovantes pour répondre aux besoins complexes de ses clients. L’entreprise est reconnue pour son expertise technique et son engagement en faveur de l’innovation dans le secteur de la défense.
Durant ce stage, j’ai travaillé sur le développement d’une API visant à industrialiser et automatiser les tests sur les bancs d’essais. L’objectif était de reproduire les fonctionnalités d’une application propriétaire interne Java en utilisant Python. Malheureusement, le stage a été écourté en raison d’un problème d’habilitation de sécurité.
Réalisations
L’API Python pour l’automatisation avait déjà été développée. Mon rôle consistait à l’utiliser et à explorer ses possibilités.
J’ai testé et utilisé l’API pour automatiser certaines procédures de test, ce qui a permis de réduire les interventions manuelles et d’augmenter l’efficacité des processus.
En parallèle, j’ai pris en main l’application propriétaire interne et développé plusieurs module de tests en Java pour celui-ci.
J’ai également développé des plugins sur Netbeans avec Java pour le logiciel d’analyse.
2 - Prototypage d’une application web démonstrative des modèles de ML, Technilog
Stage technique effectué entre le 22/05/2023 et le 01/09/2023 à Saint-Rémy-lès-Chevreuse.
À propos de Technilog
Technilog est une société de services spécialisée dans le développement de solutions logicielles pour l’intégration d’objets industriels connectés ou l’IIOT (« Industrial Internet of Things »). Technilog propose deux solutions logicielles phares : Dev I/O, un logiciel de télégestion et supervision qui unifie et traite les données des équipements connectés, et Web I/O, une plateforme permettant la supervision et le contrôle des objets connectés sur diverses plateformes.
Dans le cadre de l’évolution des solutions IoT proposées par Technilog, une nouvelle version de leur produit phare, Web I/O, a été développée. Cette version intègre des fonctionnalités avancées, notamment des outils d’intelligence artificielle (IA). Pour illustrer ces outils, une application web a été créée afin de démontrer les cas d’utilisation et les capacités de cette nouvelle version.
Réalisations
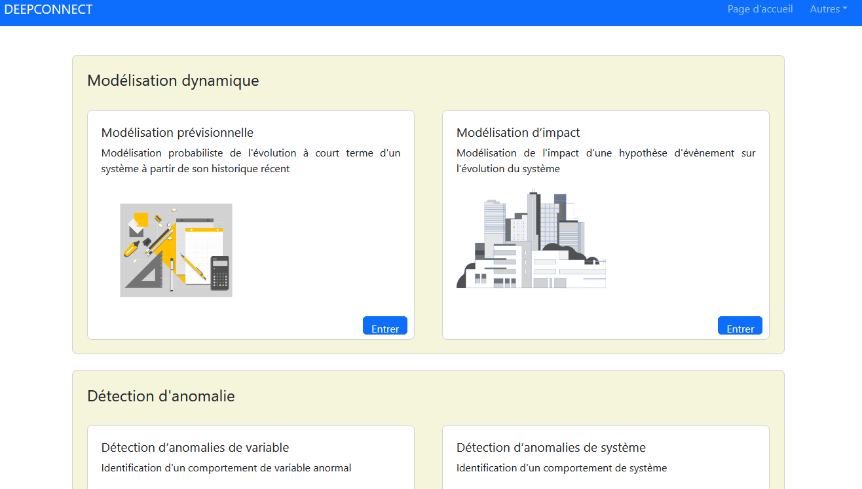
Une première version de ce site démonstrateur a été réalisée par le stagiaire précédent. Dans cette version, les fonctionnalités de qualification des données et la détection d’anomalies variables ont été implémentées. De plus, l’infrastructure nécessaire pour l’hébergement web de l’application a été mise en place. Mon rôle consistait à ajouter de nouvelles fonctionnalités et à participer aux réunions de conception des pages web :
Détection d’anomalies : Reposant sur l’apprentissage machine sur l’historique des données, cette fonctionnalité permet de déterminer si une valeur se comporte de manière inhabituelle.
Simulation prévisionnelle : Similairement à la détection d’anomalies, cette fonctionnalité utilise l’apprentissage machine sur l’historique des données. À partir de cet apprentissage et des valeurs précédemment obtenues, on peut déterminer un modèle et anticiper les valeurs futures.
Étude d’impact : Permet d’évaluer l’impact que les différentes variables ont entre elles, ainsi que les relations entre ces variables, fournissant une compréhension approfondie des influences mutuelles de ces composants.
Amélioration « Quality Of Life » : Ajout de fonctionnalités d’authentification et de mise à jour des modèles.
Approfondissement des connaissances : Étude approfondie de divers modèles d’intelligence artificielle.
2.1 - Implémentation de l'application web
Dans cette partie, nous allons voir les aspects techniques de l’application web. Le framework de développement est « Dash », un framework Python permettant de créer des applications webs.
Introduction à Dash
Dash est un framework Python permettant de créer des applications web interactives. Il fonctionne avec des layouts et des callbacks. Dans notre implémentation, nous utilisons également la bibliothèque Plotly pour la visualisation des données et des graphiques
Le framework fonctionne avec des layouts et des callbacks, ces composants définissent l’apparence et les fonctionnalités de l’application.
Layouts
Les layouts définissent l’apparence de l’application. Ils sont constitués d’éléments HTML classiques ou de composants interactifs issus de modules spécifiques. Un layout est structuré comme un arbre hiérarchique de composants, permettant l’imbrication d’éléments.
Dash est déclaratif, ce qui signifie que tous les composants possèdent des arguments qui les décrivent. Les arguments peuvent varier selon le type de composant. Les principaux types sont les composants HTML (dash.html) et les composants Dash (dash.dcc).
Les composants HTML disponibles incluent tous les éléments HTML standard, avec des attributs comme style, class, id, etc. Les composants Dash génèrent des éléments de haut niveau tels que des graphiques et des sélecteurs.
Callbacks
Les callbacks sont des fonctions automatiquement appelées lorsqu’un composant d’entrée (input) change. Ils affichent le résultat des fonctions vers un composant de sortie (output).
Les callbacks utilisent le décorateur @callback pour spécifier les inputs et outputs, correspondant aux id des composants et aux propriétés à mettre à jour. Chaque attribut d’un composant peut être modifié en tant que output d’un callback, en réponse à une interaction avec un composant input. Certains composants, comme les sliders ou les dropdowns, sont déjà interactifs et peuvent être utilisés directement comme inputs.
Exemple de code
Voici un exemple de code illustrant l’utilisation de Dash et Plotly :
Documentation
fromdashimportDash,html,dcc,callback,Output,Inputimportplotly.expressaspximportpandasaspd# Chargement des donnéesdf=pd.read_csv('https://raw.githubusercontent.com/plotly/datasets/master/gapminder_unfiltered.csv')# Initialisation de l'application Dashapp=Dash()# Définition du layout de l'applicationapp.layout=html.Div([html.H1(children='Title of Dash App',style={'textAlign':'center'}),dcc.Dropdown(df.country.unique(),'Canada',id='dropdown-selection'),dcc.Graph(id='graph-content')])# Définition du callback pour mettre à jour le graphique@callback(Output('graph-content','figure'),Input('dropdown-selection','value'))defupdate_graph(value):# Filtrer les données en fonction de la sélection du paysdff=df[df.country==value]# Créer un graphique en ligne avec Plotly Expressreturnpx.line(dff,x='year',y='pop')# Exécution de l'applicationif__name__=='__main__':app.run(debug=True)
2.2 - Modèles utilisés
Dans cette partie, nous explorerons les aspects techniques des modèles utilisés dans le projet. Bien que je ne participe pas personnellement à leur élaboration
Les modèles de Machine Learning et de Deep Learning utilisés pour les fonctionnalités implémentées incluent des modèles de prévision de séries chronologiques et des modèles auto-encoders.
Prévision de Séries Chronologiques (« Time Series Forecasting »)
Les modèles de prévision de séries chronologiques permettent de prévoir ou prédire des valeurs futures sur une période donnée. Ils sont développés à partir de l’historique des données pour prédire les valeurs futures.
Une série chronologique est un ensemble de données ordonnées dans le temps, comme des mesures de température prises chaque heure pendant une journée.
Les valeurs prédites sont basées sur l’analyse des valeurs et des tendances passées, en supposant que les tendances futures seront similaires aux tendances historiques. Il est donc crucial d’examiner les tendances dans les données historiques.
Les modèles effectuent des prédictions basées sur une fenêtre d’échantillons consécutifs. Les caractéristiques principales des fenêtres d’entrée incluent le nombre de points horaires et leurs étiquettes, ainsi que le décalage horaire entre eux. Par exemple, pour prédire les 24 prochaines heures, on peut utiliser 24 heures de données historiques (24 points pour les fenêtres avec un intervalle d’une heure).
Les modèles d’auto-encodeurs sont des réseaux de neurones conçus pour copier leur entrée vers leur sortie. Ils encodent d’abord les données d’entrée en une représentation latente de dimension inférieure, puis décodent cette représentation pour reconstruire les données. Ce processus permet de compresser les données tout en minimisant l’erreur de reconstruction.
Dans notre cas, ces modèles sont entraînés pour détecter les anomalies dans les données. Entraînés sur des cas normaux, ils présentent une erreur de reconstruction plus élevée lorsqu’ils sont confrontés à des données anormales. Pour détecter les anomalies, il suffit de définir un seuil d’erreur de reconstruction.
Conclusions
Ces modèles jouent un rôle crucial dans le projet en permettant des prévisions précises et la détection d’anomalies. Bien que je n’aie pas directement participé à leur développement, ce stage m’a offert une opportunité précieuse d’approfondir mes connaissances en machine learning et de comprendre l’importance de ces modèles dans des applications réelles. Ces outils permettent non seulement d’anticiper les tendances futures, mais aussi d’identifier des comportements inhabituels, contribuant ainsi à une prise de décision plus éclairée et proactive, ce qui est pertinent pour l’IoT.
2.3 - Travail effectué
Nous allons voir les réalisations faites pendant ce stage et les différentes fonctionnalités qui ont été implémentés
Nous allons voir les réalisations faites pendant ce stage et les différentes fonctionnalités qui ont été implémentées.
Réalisations
Comme indiqué dans la page sommaire, une première version du site a déjà été implémentée par le stagiaire précédent. Dans cette version, les fonctionnalités de qualification des données et de détection d’anomalies variables ont été mises en place. De plus, l’infrastructure nécessaire à l’hébergement web de l’application a été installée. Cette infrastructure est hébergée sur OVHCloud, utilisant une distribution Ubuntu 22.04, et l’application est déployée avec Flask.
Pour ce stage, les fonctionnalités manquantes devront être implémentées, notamment la simulation prévisionnelle, la détection d’anomalies systémiques, et l’étude d’impact. De plus, des améliorations de la qualité de vie (QOL) seront apportées.
2.3.1 - Simulation Prévisionnelle
Nous allons voir les réalisations faites pour la partie “Simulation Prévisionelle”.
L’implémentation de la prévision s’est faite de la même manière que les autres fonctionnalités : création du layout, définition des callbacks, et mise en place du container associé. Cette approche a été appliquée à toutes les nouvelles fonctionnalités.
Cette fonctionnalité vise à présenter les différents modèles disponibles pour la prédiction de variables telles que la température, la pression, la puissance, etc. Les modèles sont entraînés sur des données provenant de capteurs de Technilog, de clients, ou de sources artificielles. La fonctionnalité comprend deux onglets :
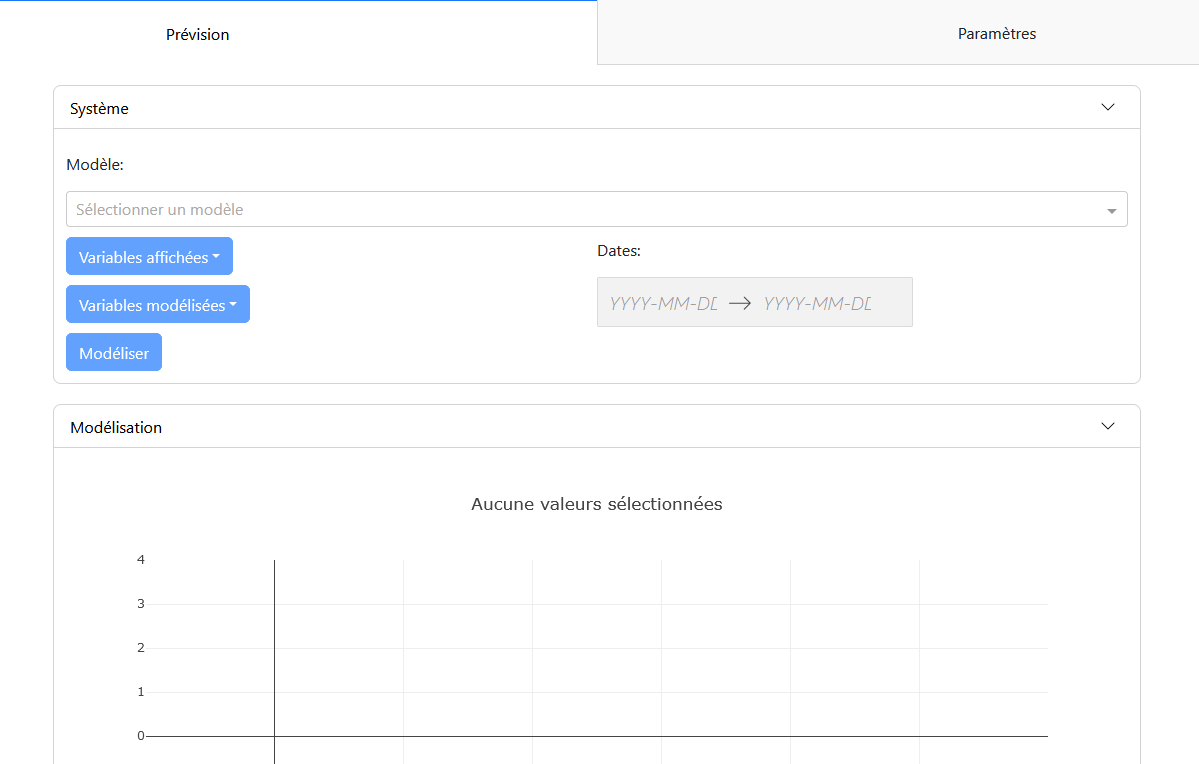
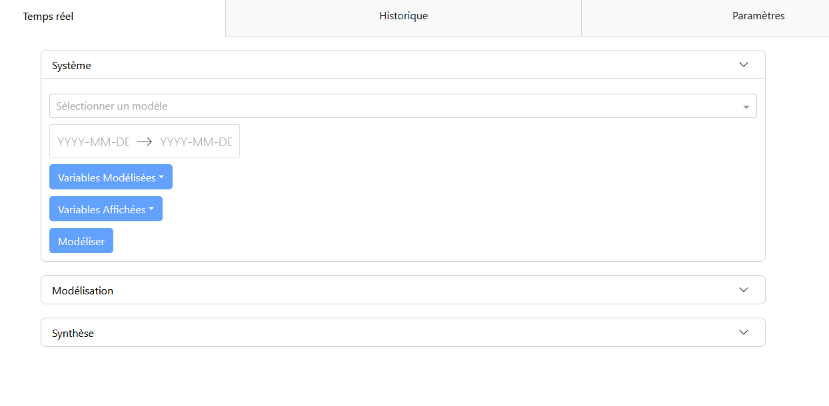
Onglet « Prévision » : Cet onglet contient le panneau de configuration « Système » et le panneau de modélisation « Modélisation ».
Panneau de Configuration : Permet de sélectionner les paramètres de modélisation, tels que le modèle, les variables d’entrée, les variables à afficher, les variables à modéliser, et la période d’étude. Une fois les variables sélectionnées, il est possible d’effectuer la prédiction et de visualiser la modélisation.
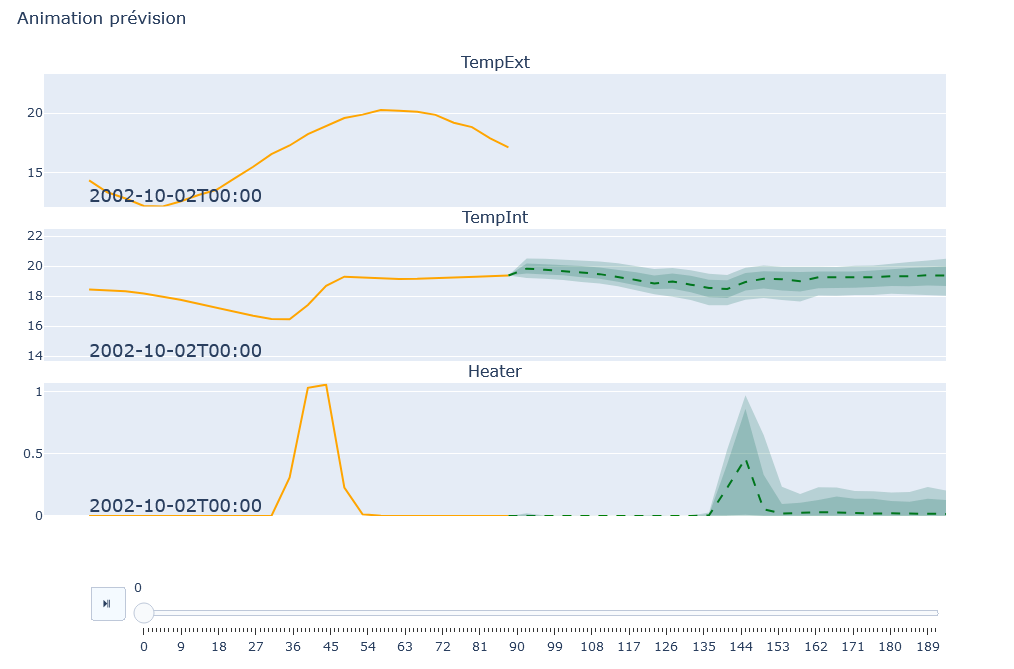
Panneau de Modélisation : Affiche les graphiques de modélisation pour chaque variable. Les graphiques montrent les données réelles en orange et les prédictions avec incertitude en vert. Des boutons de contrôle permettent de gérer l’animation, si cette option est activée.
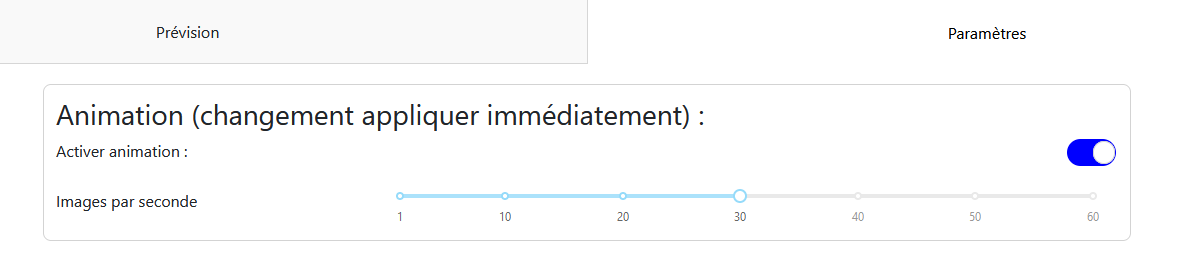
Onglet « Paramètres » : Contient les paramètres pour l’animation de la modélisation, tels que l’activation de l’animation et le nombre d’images par seconde. Ces options sont sauvegardées et appliquées à tous les modèles de la fonctionnalité.
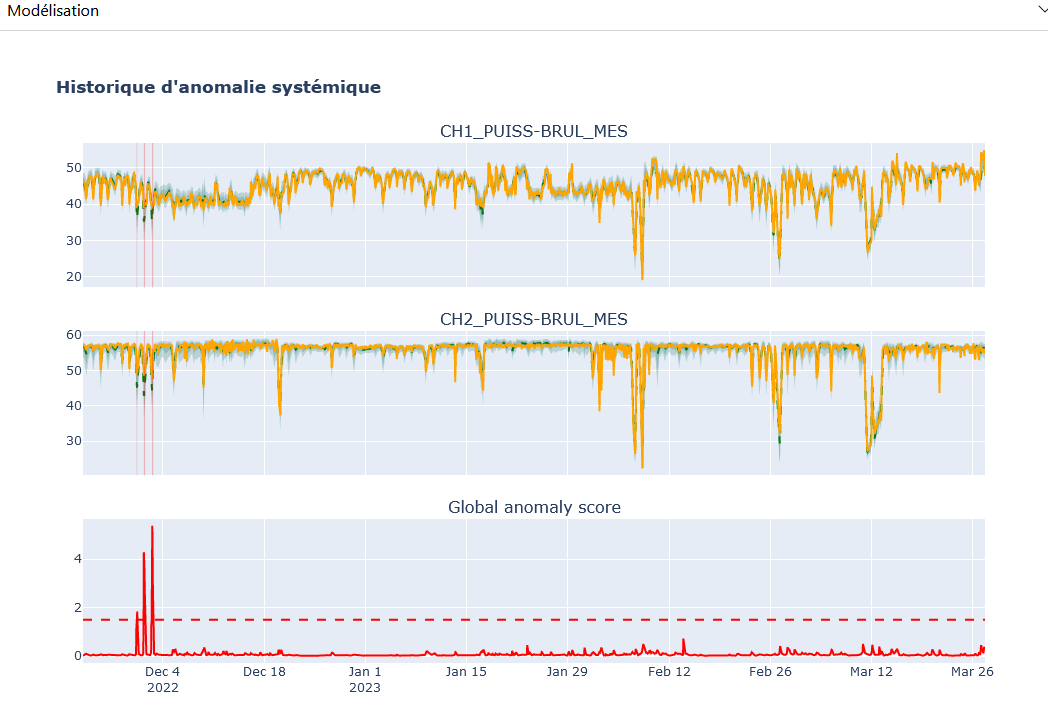
2.3.2 - Détection d’anomalies de système
Cette fonctionnalité permet de détecter les anomalies en temps réel et dans les données historiques.
Pour la détection d’anomalies de système, trois onglets sont disponibles : « Temps réel », « Historique », et « Paramètres ». Les onglets « Temps réel » et « Historique » correspondent à différents cas d’utilisation de la fonctionnalité.
Onglet « Temps réel »
Dans l’onglet « Temps réel », on trouve les panneaux de configuration « Système », de modélisation « Modélisation », et de bilan « Synthèse ».
Panneau de Configuration : Permet de sélectionner le modèle, les variables modélisées (variables surveillées pour déterminer les anomalies), les variables affichées (variables visibles dans le panneau de modélisation), et la période de mesure (dates de début et de fin). Des valeurs par défaut existent en fonction du modèle sélectionné.
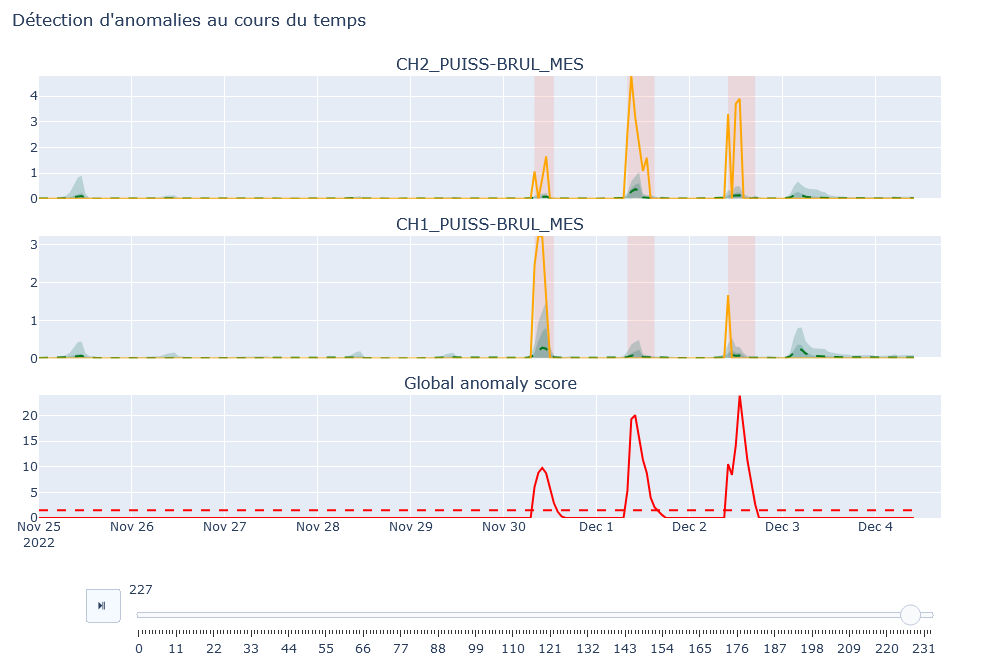
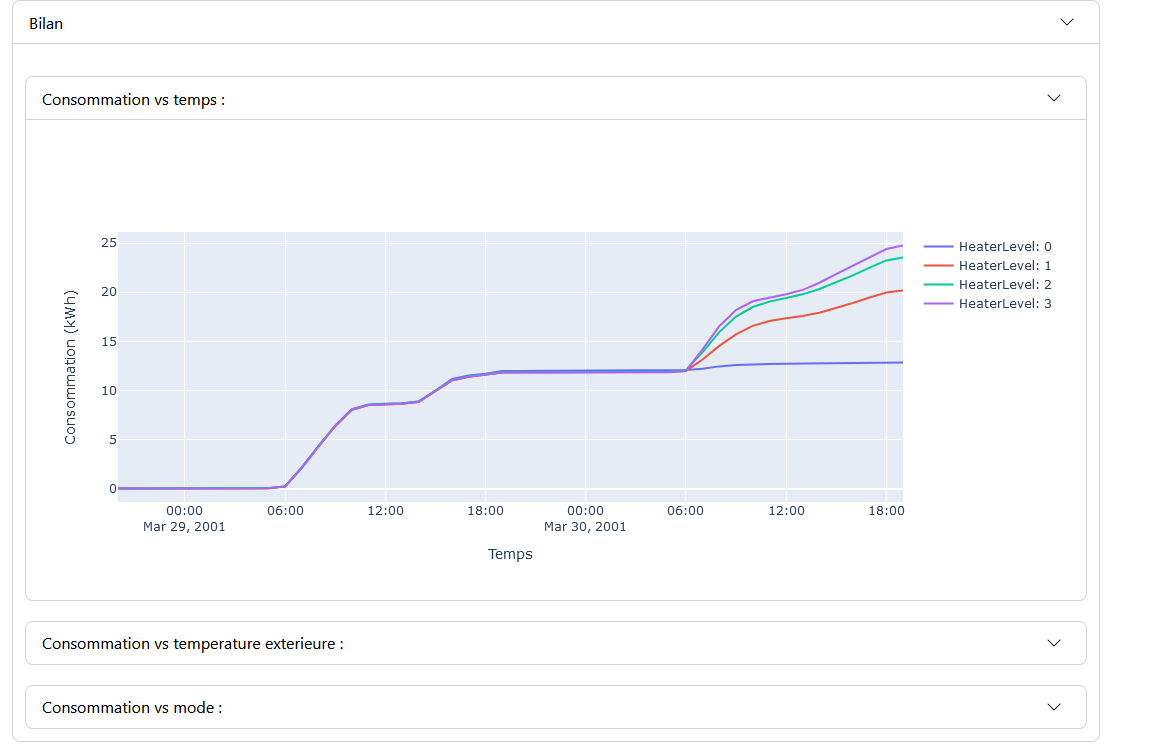
Panneau de Modélisation : Affiche les graphiques des valeurs sélectionnées avec leurs modélisations. Si le seuil d’anomalie est activé dans l’onglet « Paramètres », un graphique du score d’anomalie est également affiché, mettant en évidence les zones où le score dépasse le seuil.
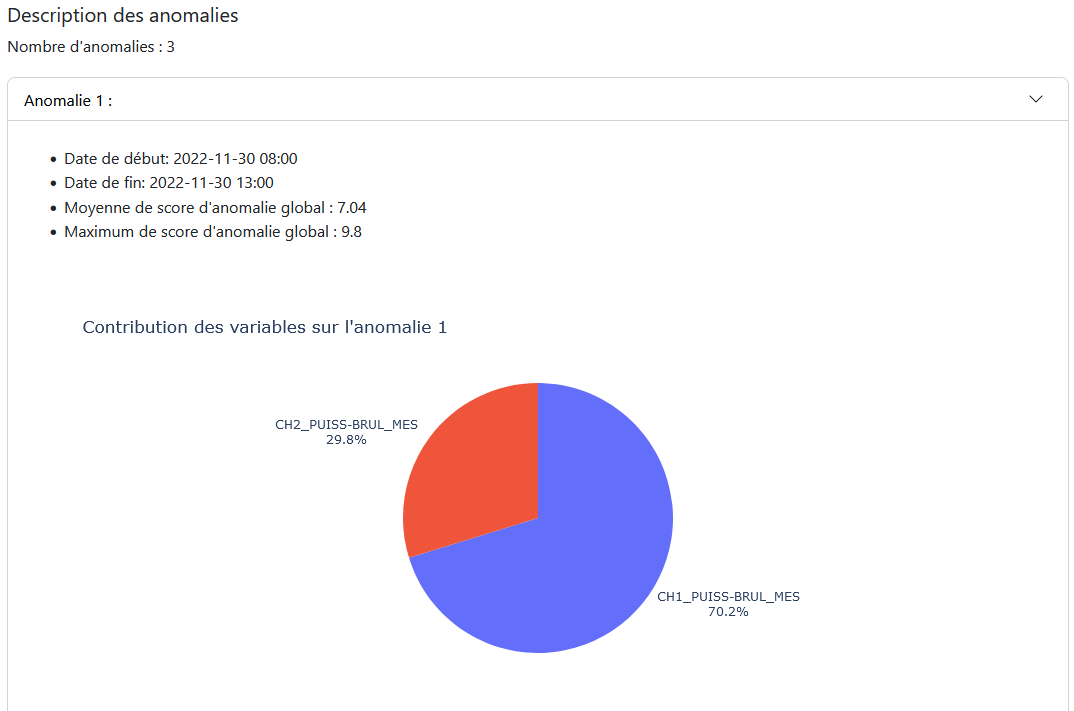
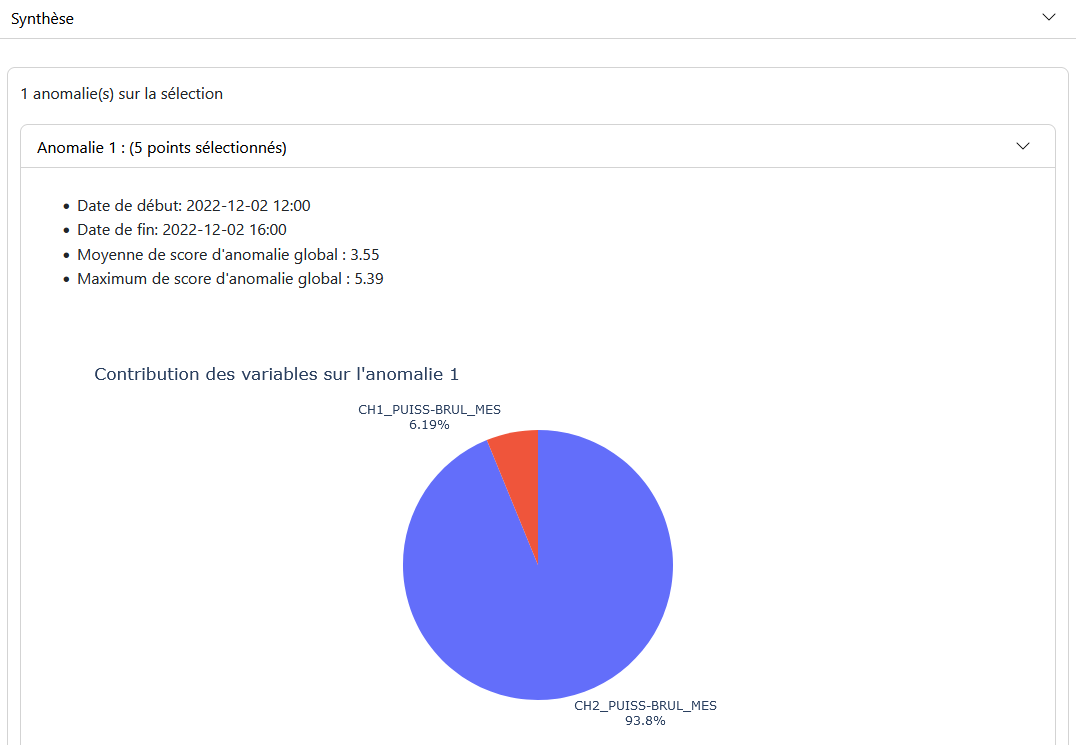
Panneau de Synthèse : Fournit une description des anomalies sur la période donnée et la contribution des variables modélisées à ces anomalies.
Onglet « Historique »
Dans l’onglet « Historique », on retrouve également les panneaux de configuration « Système », de modélisation « Modélisation », et de bilan « Synthèse ».
Panneau de Configuration : Similairement dans l’onglet « Temps réel » avec les mêmes choix. Permet de choisir le modèle, les variables modélisées, et les variables affichées. Contrairement au mode « Temps réel », il n’y a pas de sélection de période, car l’analyse couvre toute la période des données disponibles.
Panneau de Modélisation : Affiche les résultats en fonction des paramètres sélectionnés. L’utilisateur peut sélectionner une période spécifique en cliquant et en maintenant sur la modélisation obtenue.
Panneau de Synthèse : Affiche les résultats des anomalies pour la période sélectionnée, avec des descriptions des anomalies et la contribution des variables modélisées.
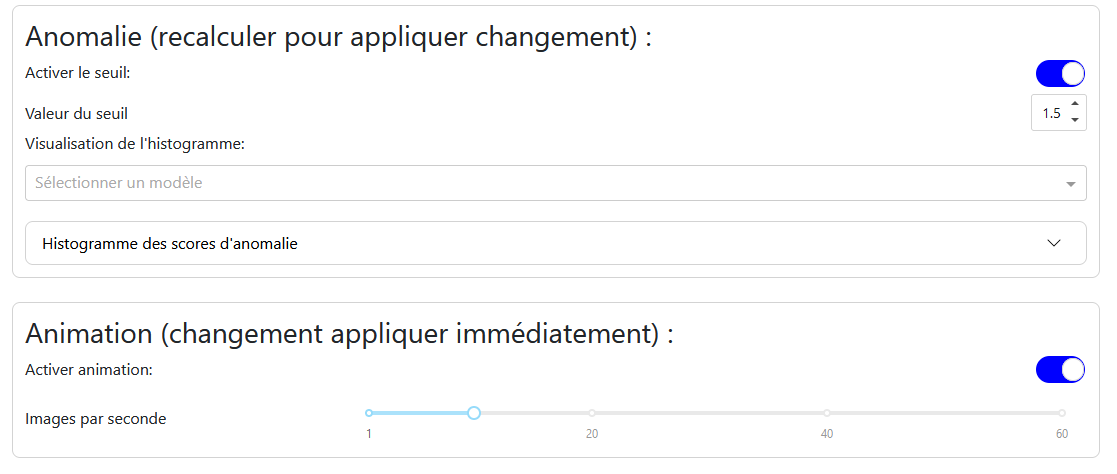
Onglet « Paramètres »
Anomalie : Permet d’activer le seuil d’anomalie et de définir sa valeur. Un histogramme des scores d’anomalie aide à déterminer la valeur optimale du seuil.
Animation : Permet d’activer ou de désactiver l’animation et de choisir le nombre d’images par seconde.
2.3.3 - Étude d’impact
Cette fonctionnalité permet d’analyser l’impact des variables et leurs influences mutuelles.
Cette fonctionnalité permet de visualiser l’impact d’une variable, c’est-à-dire les influences des variables entre elles. Elle permet ainsi d’observer les conséquences de la modification d’une ou plusieurs variables sur les autres.
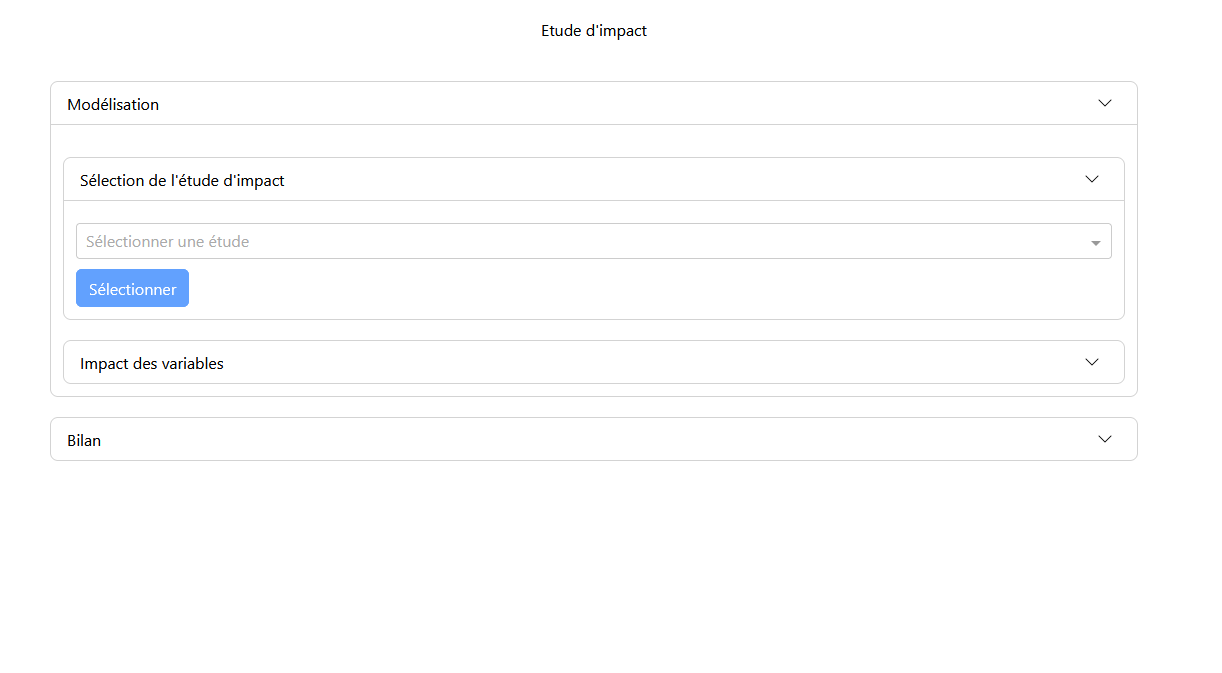
L’interface se compose uniquement de l’onglet « Étude d’impact » avec les panneaux « Modélisation » et « Bilan ». Dans le panneau « Modélisation », on trouve les sous-panneaux « Sélection de l’étude d’impact » et « Impact des variables ».
Panneau de Sélection
Dans le panneau de sélection, l’utilisateur choisit l’étude d’impact souhaitée. Une fois l’étude sélectionnée, la modélisation s’affiche dans le panneau de modélisation.
Panneau de Modélisation
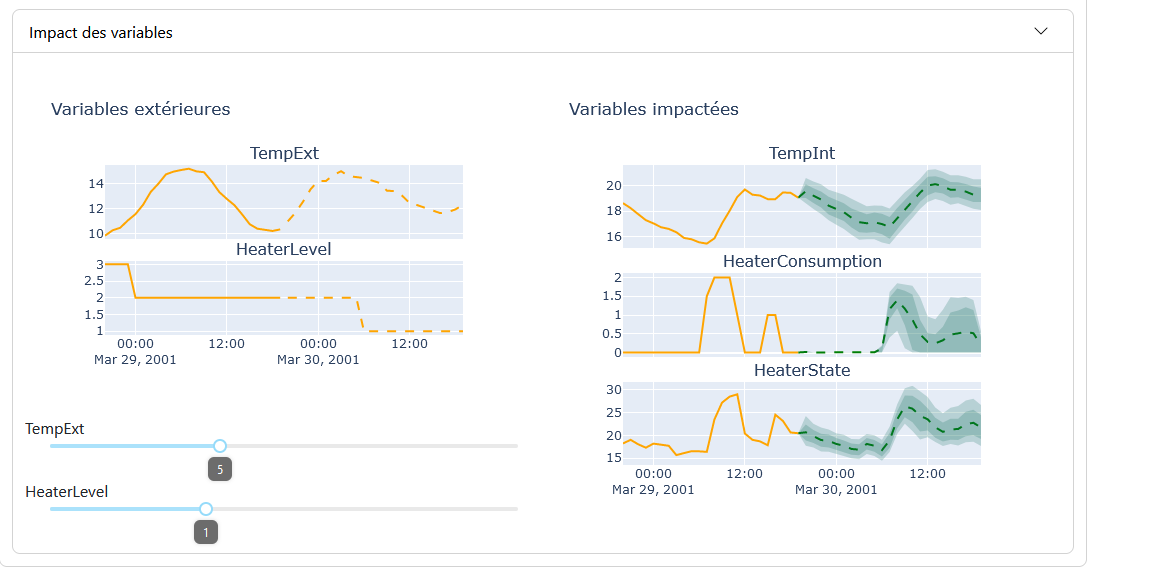
La modélisation de l’étude d’impact est présentée en deux parties :
Variables Extérieures : Ce sont les variables hypothèses qui influencent les variables impactées. Elles sont ajustées via des curseurs (sliders).
Variables Impactées : Ce sont les variables qui changent en fonction des variables extérieures/hypothèses.
À chaque modification des valeurs des variables extérieures, les graphiques des variables impactées sont régénérés. Les graphiques de modélisation sont similaires à ceux de la fonctionnalité « Modélisation prévisionnelle », avec quelques différences : pour les graphiques des variables hypothèses, la partie du graphique avec prédiction et incertitude est remplacée par une section représentant les valeurs fixées par les curseurs.
Panneau de Bilan
Dans le panneau de bilan, différents graphiques sont affichés en fonction de l’étude choisie. Ces graphiques mettent en évidence les liens et les impacts entre les variables. Lorsque les valeurs des curseurs sont modifiées, les résultats des graphiques changent en conséquence.
Comparaison avec d’autres fonctionnalités
Contrairement à d’autres fonctionnalités, il y a moins d’options disponibles (pas de choix de sélection pour la date/période ou les variables). Dans le contexte d’une application web démonstative, ces choix sont déterminés par le fichier de paramètres de l’étude.
2.3.4 - Mise à jour, QOL (« Qualities Of Life »)
Cette fonctionnalité permet d’ajouter et de mettre à jour les modèles disponibles, les fichiers de paramétrage, les jeux de données, et les fichiers de valeurs par défaut.
Mise à jour
La mise à jour permet d’ajouter et de mettre à jour les modèles disponibles, les fichiers de paramétrage, les jeux de données, et les fichiers de valeurs par défaut.
Onglets
Il y a trois onglets principaux :
Modèles : Permet de mettre à jour, d’ajouter, et de supprimer les modèles, ainsi que les études d’impact.
Jeux de données : Permet de mettre à jour, d’ajouter, et de supprimer des jeux de données.
Préconfiguration : Permet de modifier les valeurs par défaut des modèles pour leurs applications.
Onglet « Modèles »
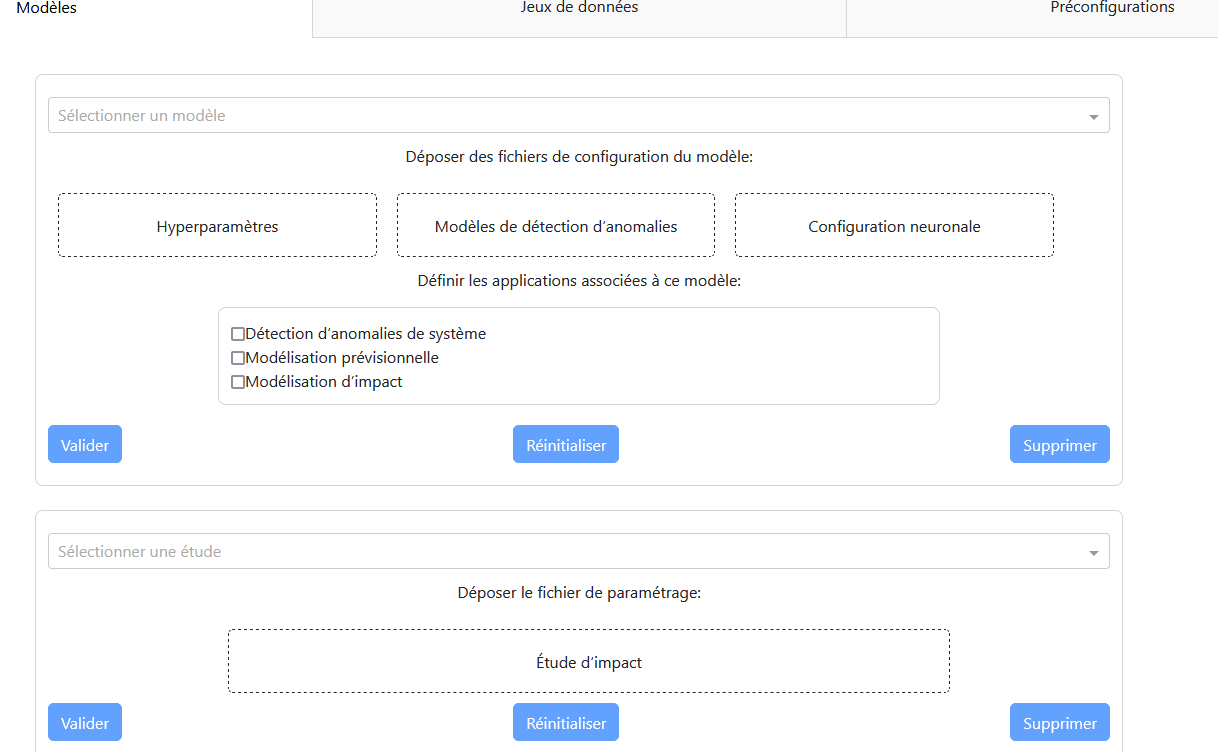
Panneau Principal :
Un menu déroulant pour sélectionner le modèle.
Une zone pour déposer les fichiers nécessaires (modèle, hyperparamètres, configuration neuronale).
Une checklist pour sélectionner les applications associées au modèle.
Trois boutons : validation, réinitialisation, et suppression.
Mise à jour d’un Modèle :
Sélectionner le modèle à mettre à jour dans le menu déroulant.
Déposer les nouveaux fichiers de configuration.
Sélectionner les applications associées.
Confirmer avec le bouton « Valider ».
Ajout d’un Modèle :
Sélectionner « Nouveau modèle » dans le menu déroulant.
Déposer les fichiers nécessaires.
Sélectionner les applications associées.
Confirmer avec le bouton « Valider ».
Suppression d’un Modèle :
Sélectionner le modèle à supprimer.
Confirmer avec le bouton « Supprimer ».
Une boîte de dialogue demandera confirmation.
Étude d’Impact :
Un menu déroulant pour sélectionner l’étude.
Une zone pour déposer le fichier de configuration.
Trois boutons : validation, réinitialisation, et suppression.
Onglet « Jeux de données »
Panneau de Configuration :
Un menu déroulant pour sélectionner le jeu de données.
Une zone pour déposer le fichier de données.
Deux boutons : validation et suppression.
Modification/Ajout d’un Jeu de Données :
Sélectionner le jeu de données à modifier ou « Nouveau jeu de données ».
Déposer le fichier de données.
Confirmer avec le bouton « Valider ».
Suppression d’un Jeu de Données :
Sélectionner le jeu de données à supprimer.
Confirmer avec le bouton « Supprimer ».
Onglet « Préconfiguration »
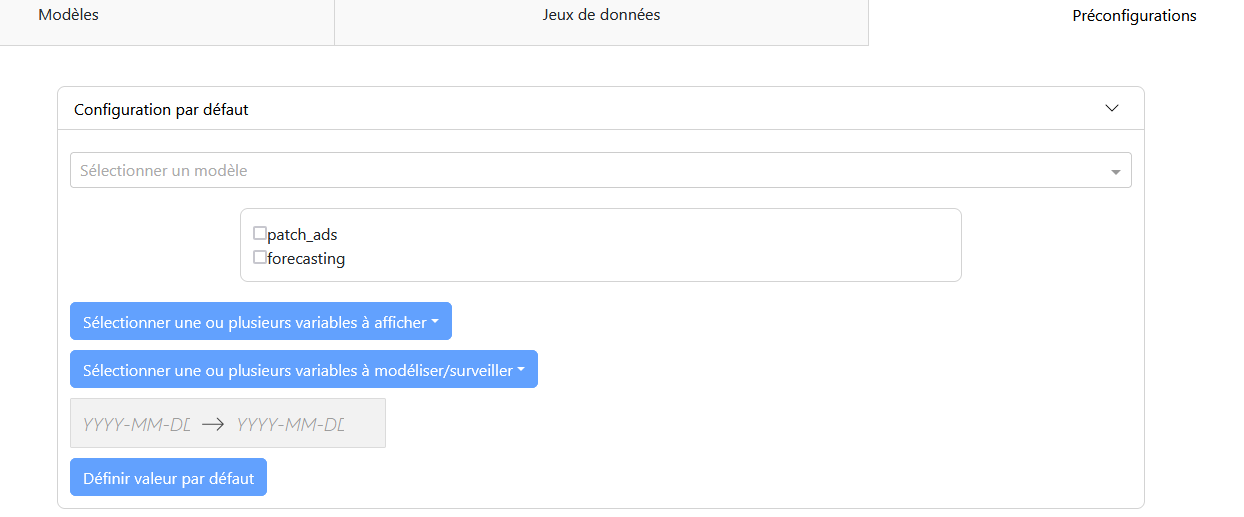
Panneau de Configuration :
Un menu déroulant pour sélectionner le modèle.
Une checklist pour sélectionner le cas d’application.
Sélection des variables à afficher et à modéliser.
Sélection de la période d’étude.
Un bouton de validation « Définir valeur par défaut ».
Configuration des Valeurs par Défaut :
Sélectionner le modèle et le cas d’application.
Configurer les paramètres de modélisation (variables affichées, modélisées, période).
Confirmer avec le bouton « Définir valeur par défaut ».
Types de Fichiers
Modèles : Fichiers .tpkl pour les modèles et .json pour les hyperparamètres.
Études d’Impact : Fichier Python avec les configurations pour l’étude.
Jeux de Données : Fichiers .csv contenant les informations utilisées par les modèles pour les prédictions.
Préconfigurations : Fichier .json avec les valeurs associées aux modèles et à la fonctionnalité utilisée.
3 - Consultant pour Colissimo pour le projet «Webhook», Artik Consulting
Stage de fin d’étude effectué entre le 12/02/2024 et le 09/08/2024 à Issy-les-Moulineaux.
À propos d’Artik Consulting
Artik Consulting est un cabinet de conseil, fondé en 2009, spécialisé en architecture des SI. Avec plus de 70 consultants, Artik Consulting accompagne les directeurs SI de grandes entreprises publiques et privées dans leurs projets de transformation digitale et la conception d’architectures répondant aux nouveaux enjeux métiers. Artik Consulting compte parmi ses principaux clients des groupes français tels que La Poste, BNP Paribas, Covéa, Kering, et collabore également avec des start-ups et des universités.
J’ai rejoint Artik Consulting pour mon stage de fin d’année. J’ai d’abord suivi une formation interne sur diverses technologies, me permettant d’acquérir une base solide. En complément, j’ai participé à l’élaboration d’une réponse à un appel d’offres de l’ESCP.
L’ESCP souhaite implémenter de nouvelles fonctionnalités de visualisation et d’analyse, et faciliter les échanges entre l’école et ses différents interlocuteurs (candidats, étudiants, etc.). Les exigences incluent l’utilisation d’une base de données en étoile et de l’outil de visualisation Jaspersoft.
J’ai été missionné chez La Poste Colis (Colissimo) et intégré dans la Squad 1 pour travailler sur un projet assigné : Webhook. Ce projet consiste à implémenter une nouvelle méthode de suivi en temps réel des colis, reposant sur des webhooks permettant de mettre à jour l’état d’avancement des colis sans requêtes directes aux serveurs. Cette solution cible les entreprises (B2B) ayant un volume important de colis à suivre, réduisant ainsi leur impact sur les serveurs de Colissimo et optimisant leur performance. Un MVP (« Minimum Viable Product ») du projet a déjà permis de réduire le nombre d’appels quotidiens de 5,9 millions à 1,7 million, soit une réduction de trafic de 70 %.
Réalisations
Lors de ma formation à travers des mini projets, j’ai pris en main :
Angular, un framework JavaScript pour le développement de pages web dynamiques.
Spring, un framework Java pour créer des services back-end comme des API.
Kafka, pour le traitement de flux de données en temps réel.
Spark, pour l’analyse de grandes quantités de données.
Elasticsearch, pour l’indexation et la recherche de données.
Kibana, pour la visualisation de ces données.
Pour la rédaction de la réponse pour l’ESCP, il a été décidé de créer des exemples de dashboards similaires au cas d’utilisation de l’ESCP. Pour cela, nous avons pris exemple avec une association caritative avec des donations, des donateurs, des promesses de don et des campagnes publicitaires. J’ai été en charge de la génération de ces données à l’aide de la librairie Python « Faker » et d’une étude préalable sur les différences de donations selon la population et le pays pour obtenir des données réalistes. De plus, j’ai pris en main les outils Talend pour la transformation de la base de données en étoile et exploré les différentes possibilités offertes par Jaspersoft Studio et Server.
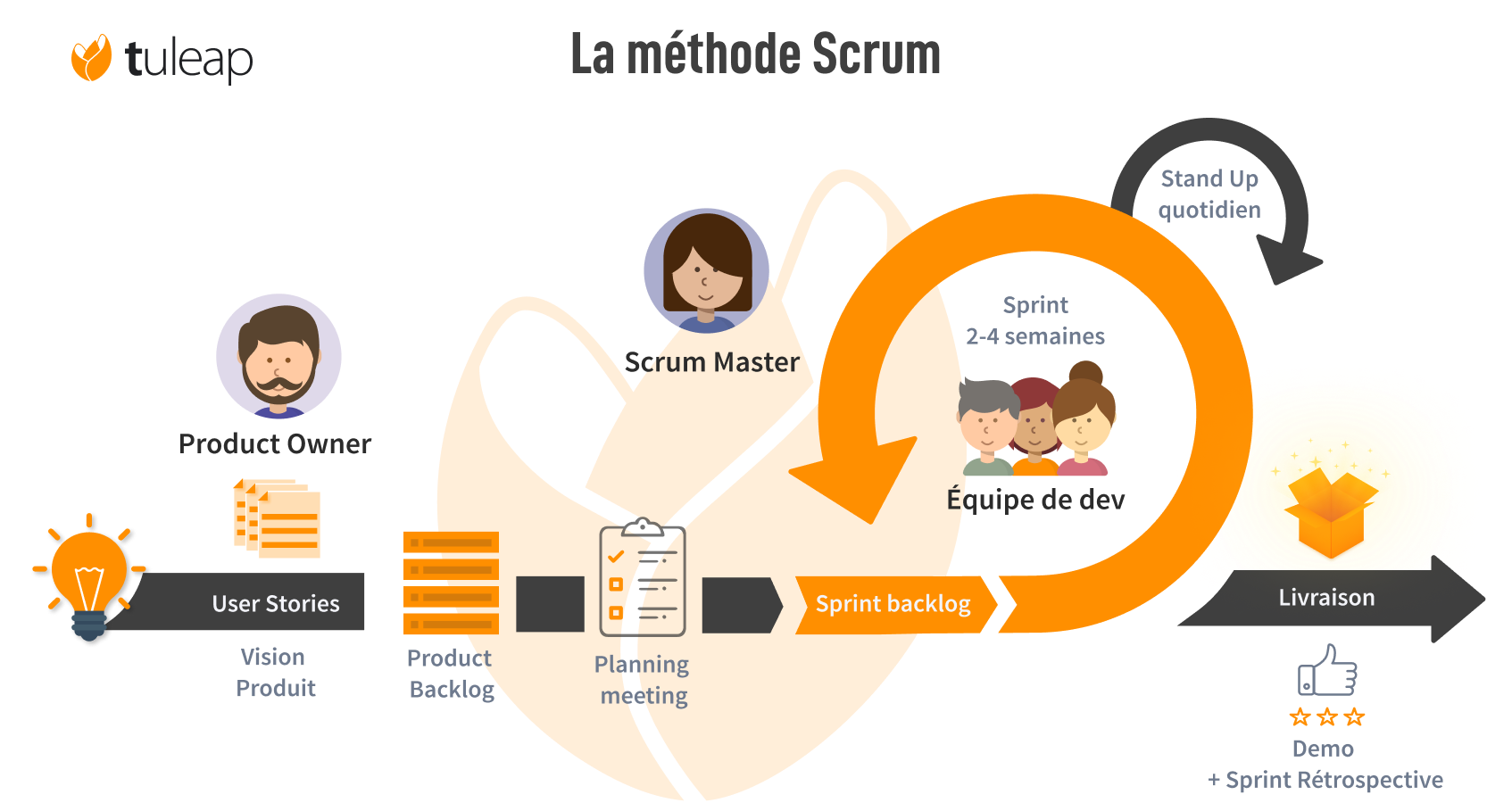
Pendant ma mission à La Poste Colis (Colissimo), en intégrant la Squad 1, j’ai pu observer et participer aux différents processus de la méthode Agile Scrum, à la gestion de projet et au déploiement des projets sur les différents environnements dans un cadre professionnel.
Dans le cadre de l’industrialisation de ce projet et de l’amélioration continue, j’interviens dans la migration du projet vers le framework Spring Boot, notamment à travers l’implémentation de fonctionnalités à l’API, et le message mapping pour les différents topics Kafka.
3.1 - Formation interne
Dans cette partie, nous allons voir la formation reçu en interne pendant mon stage à Artik Consulting
Base technique
Pendant ce stage, j’ai reçu une formation rapide sur les différents technologies que je pourrais utiliser pour mes futures missions, ces technologies offrent une base technique vaste permettant de répondre à différents missions possible.
Cette base se reposes sur:
Angular : un framework open source TypeScript compatible avec JavaScript et maintenu par Google, est utilisé pour le développement web. Il repose sur une architecture basée sur les composants, où les différentes parties de l’interface utilisateur (ou UI, « User Interface ») sont encapsulées dans des composants réutilisables et indépendants. Angular est souvent utilisé dans le développement d’applications web à page unique (SPA, « Single Page Application ») ou d’applications web progressives (PWA, « Progressive Web App »)
Spring : un framework open source Java permettant la création de microservices et d’applications web. Il permet également de développer des applications de traitement de données, comme les processus ETL (« Extract, Transform, Load »), le traitement par lots (« batch processing »), et le traitement par événement
Kafka : une plateforme de streaming distribuée open source, conçue pour gérer des flux de données en temps réel, utilisée pour le traitement en temps réel, la collecte de journaux (« logs »), la construction de pipelines de données, et l’intégration de données. Kafka fonctionne sur des transactions de message entre producteurs et consommateurs, avec une architecture partitionnée pour le stockage ordonné des messages
Spark : un framework puissant permet de traiter et d’analyser de vastes ensembles de données de manière rapide et efficace, en s’intégrant parfaitement avec Kafka pour assurer un flux continu et performant des informations
Elasticsearch : un moteur de recherche et d’analyse open source, permet des recherches et des analyses en temps réel avec une architecture distribuée et scalable, capable de gérer d’énormes volumes de données.
Kibana : un outil de visualisation et d’exploration de données conçu pour travailler avec Elasticsearch, permet de créer des tableaux de bord interactifs et personnalisables, affichant des visualisations de données en temps réel
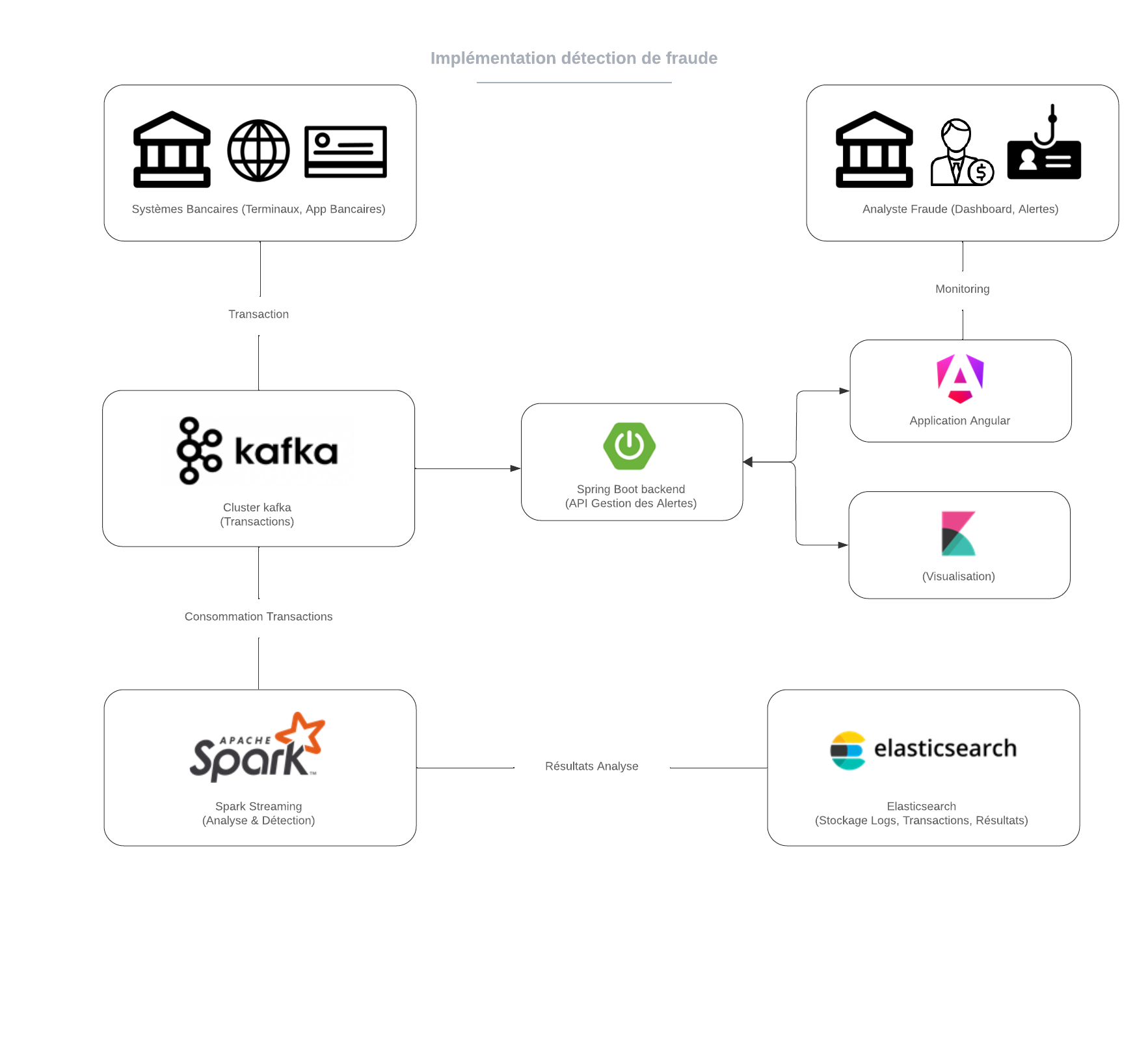
On peut synthètiser ces technologies avec un exemple concret:Dans cet exemple, on souhaite implémenter un système de détection et d’analyse de fraude:
Pour cela, les transactions bancaires sont capturées via des terminaux ou des applications bancaires, puis envoyées à un cluster Kafka pour être traitées en temps réel.
Les transactions sont ensuite consommées par Apache Spark, qui effectue des analyses pour détecter des comportements frauduleux.
Les résultats de ces analyses sont stockés dans Elasticsearch, permettant une recherche et une visualisation rapides via Kibana.
Un backend Spring Boot gère les alertes générées, tandis qu’une application Angular permet aux analystes de surveiller les transactions et de visualiser les résultats via des dashboards interactifs.
Ce système intégré assure une détection de fraude efficace et une analyse en temps réel des données.
3.2 - Rédaction à l'appel d'offre
Nous allons voir dans cette partie les détails sur l’élaboration de la réponse d’appel d’offre.
Pendant ce stage, j’ai eu l’opportunité de participer à l’écriture d’une réponse à un appel d’offre de la part de l’ESCP (“École Supérieure de Commerce de Paris”). L’ESCP est une grande école de commerce française qui possède différents sites et liens dans plusieurs pays en Europe, lui offrant ainsi un rayonnement international important. Il est donc crucial pour l’école d’avoir un suivi régulier et conséquent avec ces données (candidats, élèves, professeurs) via des rapports ou des dashboards pour aider le personnel administratif de l’école. L’ESCP est donc à la recherche d’une équipe capable de mettre en place une infrastructure de récupération de données, d’effectuer des manipulations avec ces dernières, et de créer des rapports dynamiques et pertinents par rapport à ces données.
Le groupe était constitué d’un consultant et de stagiaires, travaillant ensemble pour répondre aux exigences de l’appel d’offre et fournir une solution complète et optimisée.
Objectif du Projet
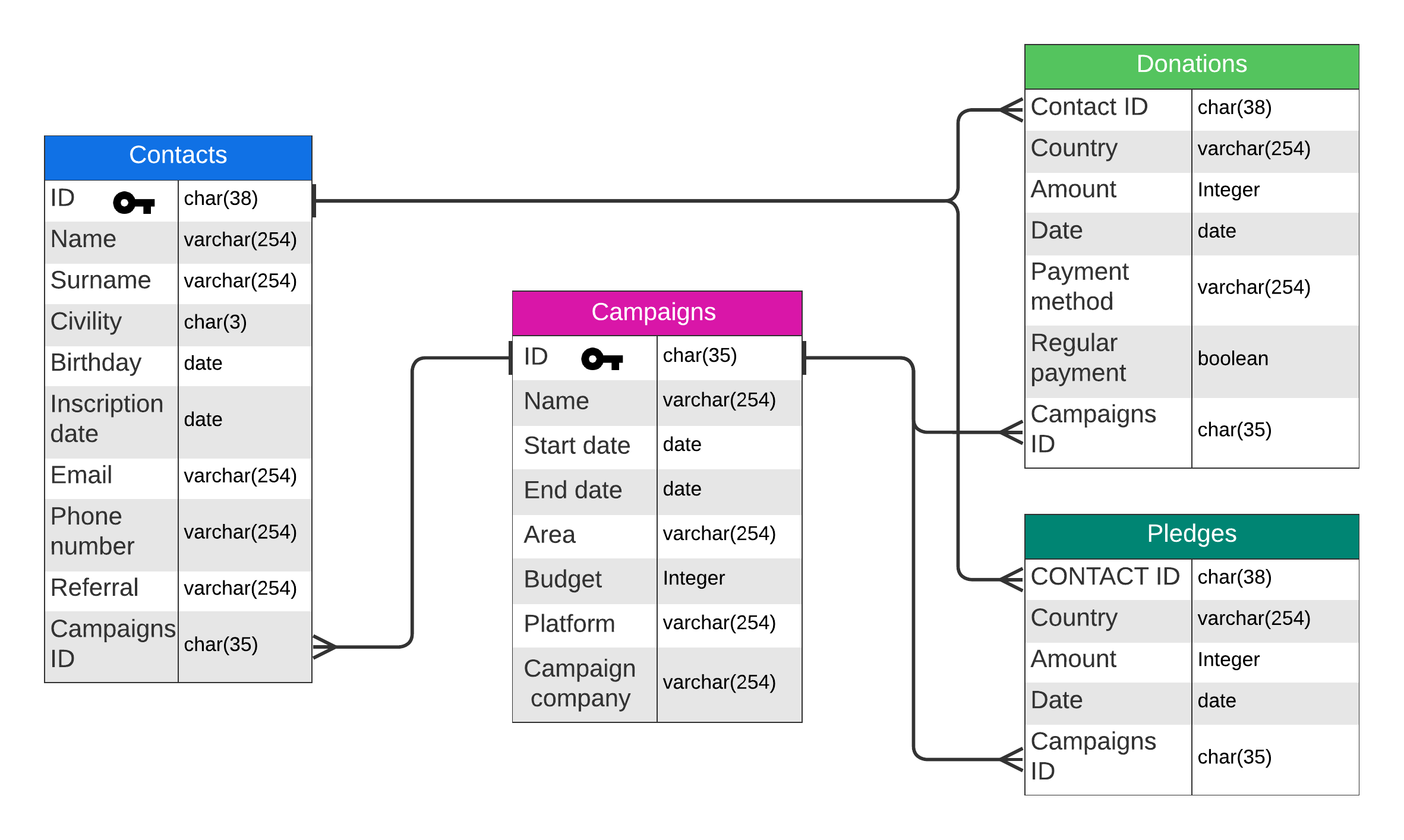
L’objectif est de réaliser un cas semblable à celle présente à l’ESCP pour montrer l’exploitation de bases de données et de graphiques en situation réelle. L’exemple choisi est celui d’une association fictive avec des donateurs, des dons, des promesses de don et des campagnes publicitaires pour créer un scénario similaire au cas de l’ESCP. Dans ce cadre, nous générons des données cohérentes pour avoir des dashboards et des rapports pertinents ; la réalisation d’une infrastructure reliant et manipulant les bases de données ; la création de rapports et de dashboards avec ces bases de données.
Conditions et Outils
Les conditions demandées incluent l’utilisation de Jaspersoft et la mise en place d’une base de données en étoile (modélisation de bases de données facilitant les requêtes complexes et les analyses en optimisant la structure des données pour les lectures, avec une table de faits au centre contenant des informations associées à des tables de dimension donnant le contexte).
Pour transformer une base de données relationnelle en un modèle en étoile, nous avons utilisé la suite Talend. Talend est une suite d’outils d’intégration de données qui permet de construire des pipelines de données robustes et efficaces. Nous l’utilisons pour des tâches d’ETL (« Extract, Transform, Extract ») afin de transformer la base de données vers le modèle en étoile pour le Data Warehouse (un data warehouse est un référentiel centralisé qui stocke des données provenant de multiples sources, facilitant ainsi l’analyse et la génération d’informations).
Nous alimentons la base de données PostgreSQL avec des données générées au préalable, via des fichiers CSV, et nous les traitons pour les mettre sur un modèle en étoile. Nous utiliserons le résultat pour créer des rapports avec Jaspersoft. Jaspersoft propose plusieurs offres : une offre cloud permettant de créer des dashboards interactifs (« Jaspersoft Cloud »), une autre offre permettant d’héberger un serveur en cloud ou sur un serveur local (« Jaspersoft Server »), et une offre logicielle permettant de créer des rapports (« Jaspersoft Studio »).
Contribution Personnelle
Ma contribution personnelle a initialement été pour la génération des données et l’exploration des différentes solutions de Jaspersoft. Pour la génération des données, j’ai tout d’abord effectué une recherche préalable pour déterminer les différents critères qui pourraient avoir un impact sur les donations et les différentes hypothèses nécessaires pour pouvoir faire cette génération de données. Le but étant d’avoir des données intéressantes à modéliser avec les dashboards et les rapports, on cherche à contraster et à faire ressortir des informations exploitables à partir des données.
3.3 - Mission Colissimo
Dans cette partie, nous allons voir les détails sur la mission effectuée à Colissimo.
Ma mission a été effectuée pour La Poste Colis, un client important et historique d’Artik Consulting. Dans cette mission, j’ai intégré la Squad 1 pour la refonte du projet « Webhook ». Cependant, ce projet n’est pas le seul sur lequel la Squad travaille. Une squad est un concept agile où une équipe de projet de petite taille, avec un ou plusieurs projets assignés, est autonome et polyvalente, avec les différents rôles métiers présents.
La Squad travaille sur les projets qui concernent Colis 360. Colis 360 est un projet de Colissimo permettant de centraliser les informations que Colissimo reçoit de la part de tiers travaillant avec La Poste Colis. Les différents tiers ont leurs propres méthodes et formats de message. Par exemple, un sous-traitant chargé du transport de colis entre les centres de tri et les centres de livraison a un format différent de celui du transporteur final vers le client. Ces messages sont totalement différents mais ont un but similaire.
Avec les différents messages centralisés vers un même format où toutes les informations des différents tiers sont présentes, on peut alors les exploiter pour assurer un meilleur suivi colis ou pour des applications tierces.
Projet Webhook
Contexte Initial
Avant que le projet « Webhook » ait été créé, il existait uniquement deux solutions pour exposer les données des suivis aux clients :
Échanges de Données Informatisés (EDI) : Les processus permettant l’échange d’informations entre les SI d’entreprises différentes. Pour faire fonctionner ces processus, il faut définir des normes entre ces entreprises, ce qui peut demander des efforts de la part des responsables SI et des experts métiers.
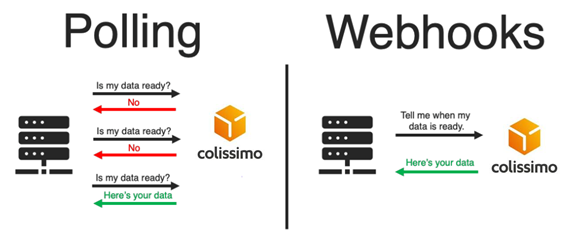
Applications Web : Permettant de faire le suivi uniquement avec des requêtes de la part des clients (« Pooling »). Lors d’un suivi en temps réel, le client envoie des requêtes à une certaine fréquence pour assurer une mise à jour du statut du colis, ce qui entraîne des appels superflus. Ces solutions n’offrent aucune possibilité de personnalisation.
Réduire les appels des services web pour le suivi des colis.
Proposer aux clients une alternative pour le suivi en temps réel.
Offrir une meilleure personnalisation des suivis en fonction des besoins clients (filtrage par type, etc.).
Diminuer les contacts avec les équipes support.
Cette solution vise des clients entreprises (B2B) tels que Amazon, Alibaba, Temu, et d’autres, des entreprises avec une forte volumétrie. Comme le nom du projet l’indique, il est basé autour de « webhooks », un rappel HTTP qui se produit lorsqu’un événement se passe. Le client n’aura plus besoin d’actualiser ou de faire des appels pour voir l’état d’avancement des colis suivis, ils sont généralement utilisés pour les notifications en temps réel.
Mécanisme de Base
Le mécanisme de base des webhooks consiste à faire une requête HTTP à une URL spécifique. Un webhook effectue un rappel HTTP vers une URL qui est configurée par le système pour recevoir des données. Alors que les API et les webhooks accomplissent tous deux la même tâche, les webhooks sont beaucoup plus efficaces pour transférer les données en réduisant de manière significative la charge de serveur par rapport aux appels API.
Une première version du projet avait pour estimation de réduire les coûts d’infrastructure en réduisant le nombre d’appels quotidiens de 5,9 millions à 1,7 million, soit une réduction du trafic de 70 %.
Refonte du Projet Webhook
Problèmes Initiaux
La version initiale du projet avait quelques problèmes :
Le projet a été initialement prévu pour un client dans le cadre d’un MVP (Minimum Viable Product).
Des erreurs de push vers un client affectaient les autres clients.
On ne pouvait pas traiter des centaines de clients en prévision des besoins futurs, cette solution n’était pas scalable.
On souhaitait remplacer le framework « Akka » (Scala/Java) par le framework Spring.
Dans cette nouvelle version, une nouvelle architecture a été implémentée pour répondre aux nouvelles exigences fonctionnelles telles que :
L’exportation des données vers des formats spécifiques aux clients logistiques.
Une gestion de la consommation des messages pour les clients.
Différents profils d’abonnement dépendant des besoins.
La possibilité aux clients de s’abonner à plusieurs API depuis un seul compte.
L’implémentation d’un système de rejeu technique et fonctionnel.
Cette nouvelle architecture se concentre sur trois axes : la scalabilité, l’adaptabilité, et l’exploitabilité. Pour cela, on utilise Spring boot avec Swagger.
Les différentes contributions au différents projets
Le code source de ce que j’ai réalisé ne peut pas être publié ici, mais des captures d’écran peuvent être présent pour accompagner les explications.
Réalisations
Pendant ce stage, j’ai eu l’opportunité d’intervenir dans deux projets, le premier a été la rédaction de la réponse à l’appel d’offre et le second a été avec ma mission à Colissimo avec le projet « Webhook ».
3.4.1 - Contribution à la réponse de l'appel d'offre
Nous allons voir les réalisations faites pour la réponse à l’appel d’offre
Génération de Données
Exploration préalable à la génération
J’ai récupéré des informations de différentes associations françaises et internationales, provenant directement de leurs sites ou sur des sites tiers comme Kaggle. En ayant récupéré ces informations, j’ai pu déterminer les informations nécessaires et celles qui ne le sont pas pour notre cas.
J’ai pu trouver la somme moyenne que les associations reçoivent pour les paiements ponctuels et réguliers. Le pourcentage des donations qui sont des paiements réguliers et ponctuels, avec une somme de 100$ pour un don ponctuel et 50$ pour un don régulier en moyenne aux États-Unis.
Et les différentes méthodes de paiements fréquemment utilisés comme les chèques, les virements bancaires, l’argent liquide ou par carte de crédit/débit. J’ai pu voir qu’il y a eu un changement récent avec la démocratisation de l’internet et des achats en ligne. Par exemple, en France, en 2010, 23% des Français donnaient en ligne contre 28% en 2020, cette dynamique est présente dans la plupart des catégories d’âge mais est plus marquée pour les personnes de moins de 35 ans avec 28% donnant en ligne, une augmentation de 13% par rapport à 2010.
De plus, l’âge du donneur moyen aux États-Unis est de 64 ans et en France de 62 ans, il est donc nécessaire de montrer cette disparité avec l’âge des donneurs.
J’ai cherché à limiter l’origine des dons à des régions spécifiques, dans notre cas, j’ai choisi l’Europe et l’Amérique du Nord. Ces zones géographiques sont intéressantes, on a un certain niveau de richesse similaire entre les deux zones mais des disparités assez prononcées à l’intérieur de ces zones, par exemple la disparité entre les États-Unis et le Mexique, et entre l’Europe de l’Ouest et de l’Est. Pour représenter ces disparités entre les pays, j’ai utilisé le PIB/par habitant de chaque pays et je l’ai normalisé par rapport aux États-Unis, c’est-à-dire qu’avec un PIB/par habitant d’environ 76 000 $, les États-Unis ont une valeur de 1.00 et que le Mexique avec un PIB/par habitant d’environ 11 500 $ a une valeur de 0.15. Ces valeurs sont utilisées comme multiplicateur pour les dons provenant des pays.
Les différentes métriques utilisées sont pertinentes mais je n’ai pas pris en compte les inégalités au sein d’un même pays, pour cela j’ai utilisé une métrique souvent utilisée en statistique, le coefficient de Gini. Le coefficient/indice de Gini est une mesure de la distribution et de la répartition d’une valeur, dans notre cas la richesse. L’indice de Gini varie entre 0 et 1, avec un coefficient de 0 correspondant à une égalité parfaite où la distribution de la variable est égale pour tous, et 1 correspondant à l’inverse, une inégalité absolue où la répartition de la valeur est accordée à un seul individu. Ce facteur est utilisé pour accentuer les maximales et les minimales des donations. Une fois ces différentes informations récoltés, j’ai pu élaborer cette base de donnée:
Python pour générer les données
Pour pouvoir générer ces données, j’ai utilisé Python avec la librairie « Faker », cette librairie est inspirée de la librairie du même nom en Ruby. Python est souvent utilisé pour la data science, il existe donc différentes librairies pour la génération de données synthétiques. J’ai utilisé la librairie « Faker » dans le cadre de ce projet. Faker est une librairie Python permettant de générer des données fictives mais avec un certain réalisme. Les avantages de Faker par rapport à d’autres librairies sont les suivants :
Localisation, c’est-à-dire l’adaptation des générateurs de la librairie à différents pays, dans notre cas, la génération de prénoms et de noms pour la table des contacts.
Variété, il existe différents générateurs à disposition pour les noms, les prénoms, la date de naissance ou l’adresse.
Personnalisable, les différents générateurs peuvent être modifiés et la possibilité de créer de nouveaux générateurs est donnée à l’utilisateur.
Sur site, pas de limites de génération comparé à des API en ligne, générations entièrement sur machine locale.
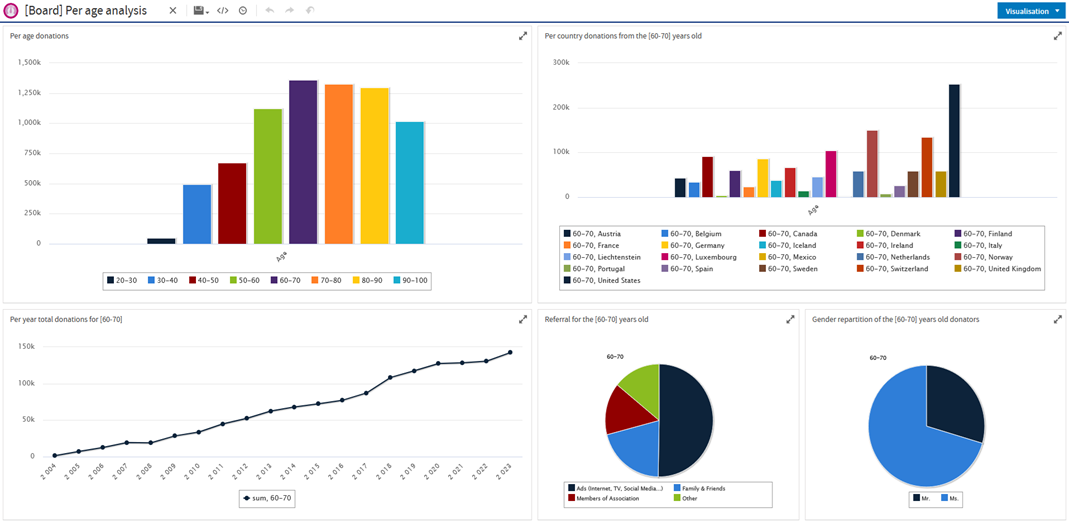
J’ai aussi exploré les outils proposés par Jaspersoft. Nous avons eu accès à un serveur Jaspersoft Server avec un serveur sur Azure VM. Jaspersoft Server permet de créer des dashboards et des rapports interactifs. Pour les outils de Jaspersoft, nous avons la possibilité de connecter différentes sources de données allant du fichier CSV à des bases de données en connexions JDBC. Dans notre cas, avec la base de données en étoile qui est stockée en PostgreSQL, nous utilisons la connexion JDBC pour connecter notre base de données pour l’exploiter. Sur Jaspersoft Server, l’interface est simple d’utilisation avec une interface moderne et avec une documentation et des tutoriels permettant un apprentissage rapide et une prise en main rapide. Jaspersoft Server permet de mettre en place des graphiques dynamiques, qui changent en fonction des actions de l’utilisateur, avec des composants fournis par Jaspersoft. Nous avons aussi découvert des limitations avec l’outil au niveau de la personnalisation des dashboards, nous ne pouvons pas éditer les titres des composants, la couleur des graphes. Nous avions une contrainte de temps ce qui nous a empêchés d’explorer l’ensemble des possibilités avec Jaspersoft Studio.
Exemple de dashboard sur Jaspersoft Server:
Jaspersoft Studio permet de créer des rapports statiques qui peuvent être remplis par des composants déjà existants et de les alimenter avec des données que l’on fournit. De manière similaire à Jaspersoft Server, nous avons connecté notre base de données avec une connexion JDBC. Jaspersoft Studio se concentre sur l’élaboration de rapports statiques qu’on peut faire en batch.
Continuation du Projet
Malheureusement, nous n’avons pas été retenus par l’ESCP, mais nous avions décidé de poursuivre le projet pour évaluer les lacunes que nous aurions pu avoir et l’intégration d’une solution de data warehousing, Snowflake.
Snowflake est une plateforme cloud de data warehousing, qui offre un large éventail d’outils permettant de gérer l’analyse de données et l’espace de stockage nécessaire à grande échelle. Elle est déployable sur plusieurs plateformes cloud populaires telles que AWS, Azure et GCP pour la flexibilité et la redondance. Elle est aussi facilement scalable dépendant de la charge de travail et indépendamment pour le stockage et la capacité de traitement. Nous avons pu facilement intégrer Snowflake avec Jaspersoft, car Jaspersoft propose un outil intégré le permettant.
Lors de la réponse à l’appel d’offre, nous nous sommes concentrés sur les dashboards interactifs proposés par Jaspersoft Server et nous avions délaissé Jaspersoft Studio, mais nous avons découvert une fonctionnalité intéressante pour une organisation comme l’ESCP. L’option d’envoyer par mail automatiquement les rapports qui ont été créés et de recevoir des notifications de confirmation de l’envoi des courriels. Pour une école où on doit produire et envoyer un large nombre de documents aux étudiants, ces options sont pertinentes et peuvent être la cause de la sélection d’un autre cabinet. Une fois terminé, j’ai été informé de ma mission et des technologies que je vais utiliser pour l’accomplir.
3.4.2 - Contribution au projet
Nous allons voir les différentes tâches effectués pour le projet « Webhook »
Contributions Personnelles
Consultation des User Stories
J’ai d’abord consulté les différentes user stories du projet « Webhook » et des autres projets pour comprendre le contexte et les aspects fonctionnels. J’ai également assisté à des réunions où mon maître de stage discutait avec le responsable produit de la mise à jour des user stories.
Mapping de Messages
L’une des premières tâches qui m’a été attribuée consistait à effectuer le mapping d’un message vers un autre. Il s’agissait de récupérer un message dans un format donné et de le convertir en un autre format pour l’envoyer à un autre composant.
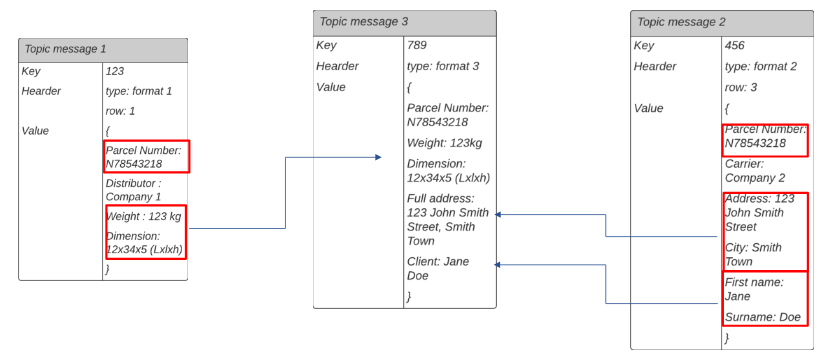
Exemple de message mapping
Dans cet exemple, nous avons initialement deux messages, «Topic message 1» et «Topic message 2», à partir desquels nous souhaitons extraire des informations. Ces informations seront utilisées pour créer un nouveau message, «Topic message 3».
Les deux messages initiaux, «Topic message 1» et «Topic message 2», sont récupérés en utilisant le numéro de colis («Parcel Number») comme identifiant commun.
Une fois ces messages récupérés, les informations nécessaires sont extraites de chacun d’eux.
Les informations extraites sont ensuite combinées pour créer le nouveau message, «Topic message 3».
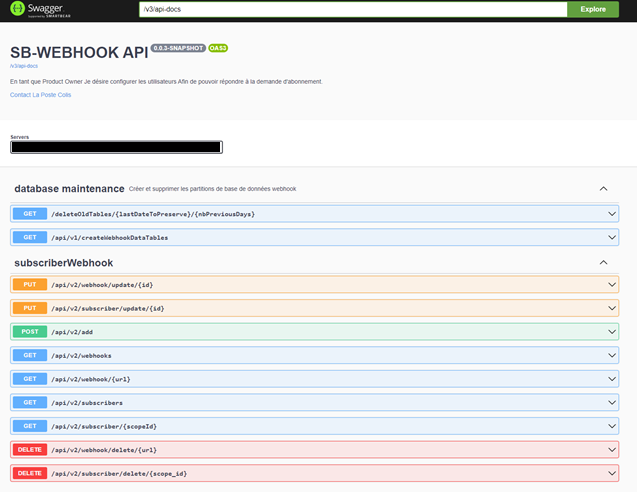
Ajout de Fonctionnalités avec Swagger
J’ai ajouté des fonctionnalités à l’API Swagger, une solution open source utilisée pour le développement et la documentation des API REST. Notre application étant développée avec Spring Boot, Swagger peut être utilisé pour documenter les différentes routes, méthodes, paramètres, et réponses de l’API.
Les fonctionnalités ajoutées incluent :
L’ajout de nouveaux « webhooks » et « subscribers » associés entre eux.
La suppression de « webhooks » et « subscribers ».
La modification et la mise à jour des « webhooks » et « subscribers » existants.
La possibilité de visualiser tous les « webhooks » et tous les « subscribers ».
La possibilité de visualiser un « webhook » spécifique à partir d’une ID ou URL, de même pour les « subscribers ».
Implémentation du Rejeu Technique
J’ai également implémenté le rejeu technique, c’est-à-dire, le renvoi des messages qui ne se sont pas correctement envoyés soit à cause d’un problème d’accès serveur, ou d’autres problèmes qui pourraient survenir. De plus, on peut l’utiliser comme outil de test pour vérifier l’existence d’un bug.
Développement de Tests
J’ai développé une suite de tests unitaires et d’intégration. Les tests unitaires ont été réalisés en utilisant JUnit et Mockito, assurant ainsi que chaque composant individuel fonctionnait comme prévu. Les tests d’intégration ont été mis en place pour valider l’interaction entre les différents modules du système.
J’ai effectué le déploiement des différents projets dans les environnements appropriés avec les différents pipelines de déploiement à disposition.
Compétences Développées
Avec ces contributions, j’ai énormément appris et développé de nombreuses compétences. En travaillant sur les user stories, j’ai acquis une compréhension approfondie de la manière dont les besoins des utilisateurs se traduisent en fonctionnalités techniques. En travaillant davantage sur Spring Boot, j’ai renforcé ce que j’ai appris pendant ma formation et les implémentations du framework dans un environnement professionnel.