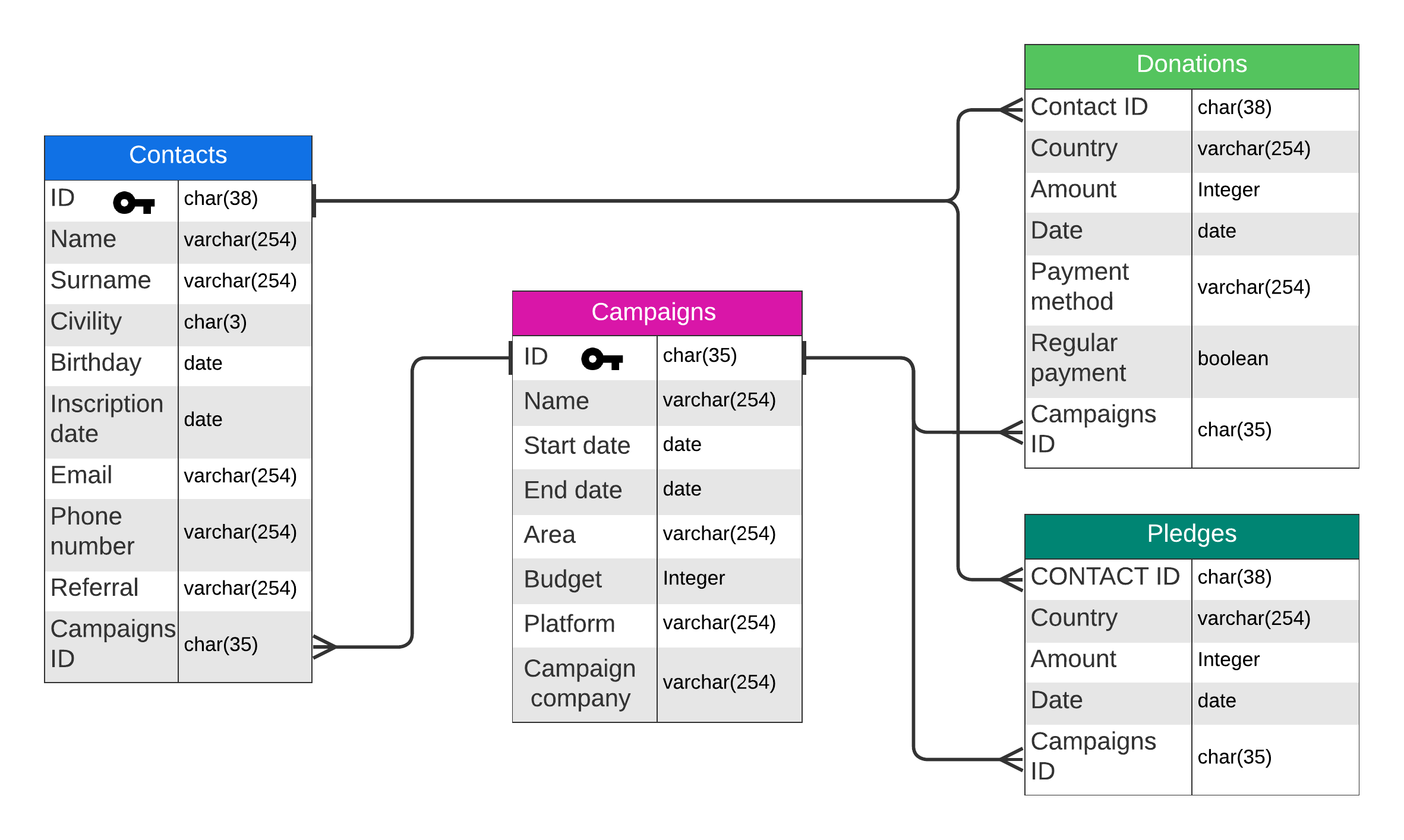
Contribution à la réponse de l'appel d'offre
Génération de Données
Exploration préalable à la génération
J’ai récupéré des informations de différentes associations françaises et internationales, provenant directement de leurs sites ou sur des sites tiers comme Kaggle. En ayant récupéré ces informations, j’ai pu déterminer les informations nécessaires et celles qui ne le sont pas pour notre cas.
J’ai pu trouver la somme moyenne que les associations reçoivent pour les paiements ponctuels et réguliers. Le pourcentage des donations qui sont des paiements réguliers et ponctuels, avec une somme de 100$ pour un don ponctuel et 50$ pour un don régulier en moyenne aux États-Unis.
Et les différentes méthodes de paiements fréquemment utilisés comme les chèques, les virements bancaires, l’argent liquide ou par carte de crédit/débit. J’ai pu voir qu’il y a eu un changement récent avec la démocratisation de l’internet et des achats en ligne. Par exemple, en France, en 2010, 23% des Français donnaient en ligne contre 28% en 2020, cette dynamique est présente dans la plupart des catégories d’âge mais est plus marquée pour les personnes de moins de 35 ans avec 28% donnant en ligne, une augmentation de 13% par rapport à 2010. De plus, l’âge du donneur moyen aux États-Unis est de 64 ans et en France de 62 ans, il est donc nécessaire de montrer cette disparité avec l’âge des donneurs.
J’ai cherché à limiter l’origine des dons à des régions spécifiques, dans notre cas, j’ai choisi l’Europe et l’Amérique du Nord. Ces zones géographiques sont intéressantes, on a un certain niveau de richesse similaire entre les deux zones mais des disparités assez prononcées à l’intérieur de ces zones, par exemple la disparité entre les États-Unis et le Mexique, et entre l’Europe de l’Ouest et de l’Est. Pour représenter ces disparités entre les pays, j’ai utilisé le PIB/par habitant de chaque pays et je l’ai normalisé par rapport aux États-Unis, c’est-à-dire qu’avec un PIB/par habitant d’environ 76 000 $, les États-Unis ont une valeur de 1.00 et que le Mexique avec un PIB/par habitant d’environ 11 500 $ a une valeur de 0.15. Ces valeurs sont utilisées comme multiplicateur pour les dons provenant des pays.
Les différentes métriques utilisées sont pertinentes mais je n’ai pas pris en compte les inégalités au sein d’un même pays, pour cela j’ai utilisé une métrique souvent utilisée en statistique, le coefficient de Gini. Le coefficient/indice de Gini est une mesure de la distribution et de la répartition d’une valeur, dans notre cas la richesse. L’indice de Gini varie entre 0 et 1, avec un coefficient de 0 correspondant à une égalité parfaite où la distribution de la variable est égale pour tous, et 1 correspondant à l’inverse, une inégalité absolue où la répartition de la valeur est accordée à un seul individu. Ce facteur est utilisé pour accentuer les maximales et les minimales des donations. Une fois ces différentes informations récoltés, j’ai pu élaborer cette base de donnée:
Python pour générer les données
Pour pouvoir générer ces données, j’ai utilisé Python avec la librairie « Faker », cette librairie est inspirée de la librairie du même nom en Ruby. Python est souvent utilisé pour la data science, il existe donc différentes librairies pour la génération de données synthétiques. J’ai utilisé la librairie « Faker » dans le cadre de ce projet. Faker est une librairie Python permettant de générer des données fictives mais avec un certain réalisme. Les avantages de Faker par rapport à d’autres librairies sont les suivants :
- Localisation, c’est-à-dire l’adaptation des générateurs de la librairie à différents pays, dans notre cas, la génération de prénoms et de noms pour la table des contacts.
- Variété, il existe différents générateurs à disposition pour les noms, les prénoms, la date de naissance ou l’adresse.
- Personnalisable, les différents générateurs peuvent être modifiés et la possibilité de créer de nouveaux générateurs est donnée à l’utilisateur.
- Sur site, pas de limites de génération comparé à des API en ligne, générations entièrement sur machine locale.
Source : Faker
Utilisation des Outils
J’ai aussi exploré les outils proposés par Jaspersoft. Nous avons eu accès à un serveur Jaspersoft Server avec un serveur sur Azure VM. Jaspersoft Server permet de créer des dashboards et des rapports interactifs. Pour les outils de Jaspersoft, nous avons la possibilité de connecter différentes sources de données allant du fichier CSV à des bases de données en connexions JDBC. Dans notre cas, avec la base de données en étoile qui est stockée en PostgreSQL, nous utilisons la connexion JDBC pour connecter notre base de données pour l’exploiter. Sur Jaspersoft Server, l’interface est simple d’utilisation avec une interface moderne et avec une documentation et des tutoriels permettant un apprentissage rapide et une prise en main rapide. Jaspersoft Server permet de mettre en place des graphiques dynamiques, qui changent en fonction des actions de l’utilisateur, avec des composants fournis par Jaspersoft. Nous avons aussi découvert des limitations avec l’outil au niveau de la personnalisation des dashboards, nous ne pouvons pas éditer les titres des composants, la couleur des graphes. Nous avions une contrainte de temps ce qui nous a empêchés d’explorer l’ensemble des possibilités avec Jaspersoft Studio.
Exemple de dashboard sur Jaspersoft Server: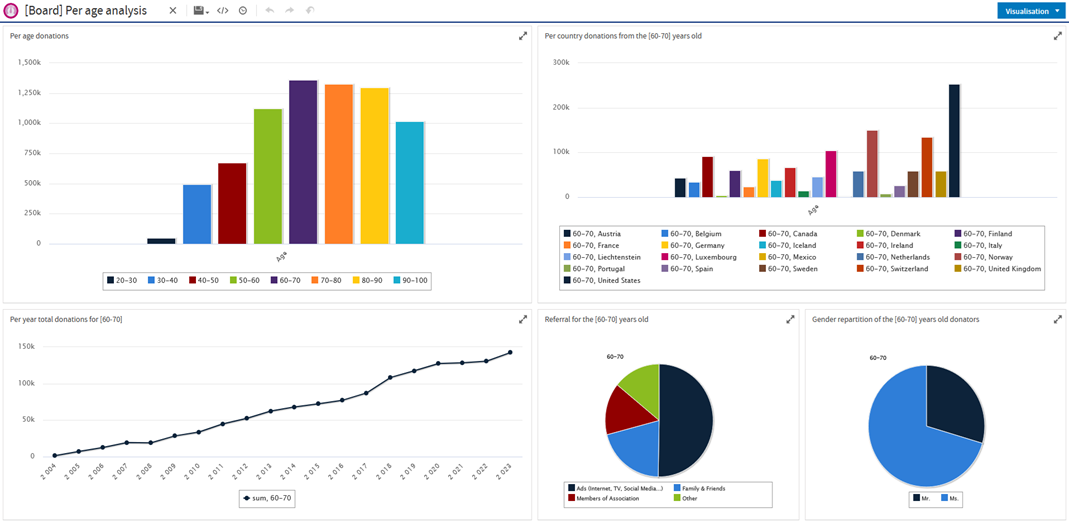
Jaspersoft Studio permet de créer des rapports statiques qui peuvent être remplis par des composants déjà existants et de les alimenter avec des données que l’on fournit. De manière similaire à Jaspersoft Server, nous avons connecté notre base de données avec une connexion JDBC. Jaspersoft Studio se concentre sur l’élaboration de rapports statiques qu’on peut faire en batch.
Continuation du Projet
Malheureusement, nous n’avons pas été retenus par l’ESCP, mais nous avions décidé de poursuivre le projet pour évaluer les lacunes que nous aurions pu avoir et l’intégration d’une solution de data warehousing, Snowflake.
Snowflake est une plateforme cloud de data warehousing, qui offre un large éventail d’outils permettant de gérer l’analyse de données et l’espace de stockage nécessaire à grande échelle. Elle est déployable sur plusieurs plateformes cloud populaires telles que AWS, Azure et GCP pour la flexibilité et la redondance. Elle est aussi facilement scalable dépendant de la charge de travail et indépendamment pour le stockage et la capacité de traitement. Nous avons pu facilement intégrer Snowflake avec Jaspersoft, car Jaspersoft propose un outil intégré le permettant.
Source : Snowflake
Lors de la réponse à l’appel d’offre, nous nous sommes concentrés sur les dashboards interactifs proposés par Jaspersoft Server et nous avions délaissé Jaspersoft Studio, mais nous avons découvert une fonctionnalité intéressante pour une organisation comme l’ESCP. L’option d’envoyer par mail automatiquement les rapports qui ont été créés et de recevoir des notifications de confirmation de l’envoi des courriels. Pour une école où on doit produire et envoyer un large nombre de documents aux étudiants, ces options sont pertinentes et peuvent être la cause de la sélection d’un autre cabinet. Une fois terminé, j’ai été informé de ma mission et des technologies que je vais utiliser pour l’accomplir.