Technilog est une société de services spécialisée dans le développement de solutions logicielles pour l’intégration d’objets industriels connectés ou l’IIOT (« Industrial Internet of Things »). Technilog propose deux solutions logicielles phares : Dev I/O, un logiciel de télégestion et supervision qui unifie et traite les données des équipements connectés, et Web I/O, une plateforme permettant la supervision et le contrôle des objets connectés sur diverses plateformes.
Dans le cadre de l’évolution des solutions IoT proposées par Technilog, une nouvelle version de leur produit phare, Web I/O, a été développée. Cette version intègre des fonctionnalités avancées, notamment des outils d’intelligence artificielle (IA). Pour illustrer ces outils, une application web a été créée afin de démontrer les cas d’utilisation et les capacités de cette nouvelle version.
Réalisations
Une première version de ce site démonstrateur a été réalisée par le stagiaire précédent. Dans cette version, les fonctionnalités de qualification des données et la détection d’anomalies variables ont été implémentées. De plus, l’infrastructure nécessaire pour l’hébergement web de l’application a été mise en place. Mon rôle consistait à ajouter de nouvelles fonctionnalités et à participer aux réunions de conception des pages web :
Détection d’anomalies : Reposant sur l’apprentissage machine sur l’historique des données, cette fonctionnalité permet de déterminer si une valeur se comporte de manière inhabituelle.
Simulation prévisionnelle : Similairement à la détection d’anomalies, cette fonctionnalité utilise l’apprentissage machine sur l’historique des données. À partir de cet apprentissage et des valeurs précédemment obtenues, on peut déterminer un modèle et anticiper les valeurs futures.
Étude d’impact : Permet d’évaluer l’impact que les différentes variables ont entre elles, ainsi que les relations entre ces variables, fournissant une compréhension approfondie des influences mutuelles de ces composants.
Amélioration « Quality Of Life » : Ajout de fonctionnalités d’authentification et de mise à jour des modèles.
Approfondissement des connaissances : Étude approfondie de divers modèles d’intelligence artificielle.
1 - Implémentation de l'application web
Dans cette partie, nous allons voir les aspects techniques de l’application web. Le framework de développement est « Dash », un framework Python permettant de créer des applications webs.
Introduction à Dash
Dash est un framework Python permettant de créer des applications web interactives. Il fonctionne avec des layouts et des callbacks. Dans notre implémentation, nous utilisons également la bibliothèque Plotly pour la visualisation des données et des graphiques
Le framework fonctionne avec des layouts et des callbacks, ces composants définissent l’apparence et les fonctionnalités de l’application.
Layouts
Les layouts définissent l’apparence de l’application. Ils sont constitués d’éléments HTML classiques ou de composants interactifs issus de modules spécifiques. Un layout est structuré comme un arbre hiérarchique de composants, permettant l’imbrication d’éléments.
Dash est déclaratif, ce qui signifie que tous les composants possèdent des arguments qui les décrivent. Les arguments peuvent varier selon le type de composant. Les principaux types sont les composants HTML (dash.html) et les composants Dash (dash.dcc).
Les composants HTML disponibles incluent tous les éléments HTML standard, avec des attributs comme style, class, id, etc. Les composants Dash génèrent des éléments de haut niveau tels que des graphiques et des sélecteurs.
Callbacks
Les callbacks sont des fonctions automatiquement appelées lorsqu’un composant d’entrée (input) change. Ils affichent le résultat des fonctions vers un composant de sortie (output).
Les callbacks utilisent le décorateur @callback pour spécifier les inputs et outputs, correspondant aux id des composants et aux propriétés à mettre à jour. Chaque attribut d’un composant peut être modifié en tant que output d’un callback, en réponse à une interaction avec un composant input. Certains composants, comme les sliders ou les dropdowns, sont déjà interactifs et peuvent être utilisés directement comme inputs.
Exemple de code
Voici un exemple de code illustrant l’utilisation de Dash et Plotly :
Documentation
fromdashimportDash,html,dcc,callback,Output,Inputimportplotly.expressaspximportpandasaspd# Chargement des donnéesdf=pd.read_csv('https://raw.githubusercontent.com/plotly/datasets/master/gapminder_unfiltered.csv')# Initialisation de l'application Dashapp=Dash()# Définition du layout de l'applicationapp.layout=html.Div([html.H1(children='Title of Dash App',style={'textAlign':'center'}),dcc.Dropdown(df.country.unique(),'Canada',id='dropdown-selection'),dcc.Graph(id='graph-content')])# Définition du callback pour mettre à jour le graphique@callback(Output('graph-content','figure'),Input('dropdown-selection','value'))defupdate_graph(value):# Filtrer les données en fonction de la sélection du paysdff=df[df.country==value]# Créer un graphique en ligne avec Plotly Expressreturnpx.line(dff,x='year',y='pop')# Exécution de l'applicationif__name__=='__main__':app.run(debug=True)
2 - Modèles utilisés
Dans cette partie, nous explorerons les aspects techniques des modèles utilisés dans le projet. Bien que je ne participe pas personnellement à leur élaboration
Les modèles de Machine Learning et de Deep Learning utilisés pour les fonctionnalités implémentées incluent des modèles de prévision de séries chronologiques et des modèles auto-encoders.
Prévision de Séries Chronologiques (« Time Series Forecasting »)
Les modèles de prévision de séries chronologiques permettent de prévoir ou prédire des valeurs futures sur une période donnée. Ils sont développés à partir de l’historique des données pour prédire les valeurs futures.
Une série chronologique est un ensemble de données ordonnées dans le temps, comme des mesures de température prises chaque heure pendant une journée.
Les valeurs prédites sont basées sur l’analyse des valeurs et des tendances passées, en supposant que les tendances futures seront similaires aux tendances historiques. Il est donc crucial d’examiner les tendances dans les données historiques.
Les modèles effectuent des prédictions basées sur une fenêtre d’échantillons consécutifs. Les caractéristiques principales des fenêtres d’entrée incluent le nombre de points horaires et leurs étiquettes, ainsi que le décalage horaire entre eux. Par exemple, pour prédire les 24 prochaines heures, on peut utiliser 24 heures de données historiques (24 points pour les fenêtres avec un intervalle d’une heure).
Les modèles d’auto-encodeurs sont des réseaux de neurones conçus pour copier leur entrée vers leur sortie. Ils encodent d’abord les données d’entrée en une représentation latente de dimension inférieure, puis décodent cette représentation pour reconstruire les données. Ce processus permet de compresser les données tout en minimisant l’erreur de reconstruction.
Dans notre cas, ces modèles sont entraînés pour détecter les anomalies dans les données. Entraînés sur des cas normaux, ils présentent une erreur de reconstruction plus élevée lorsqu’ils sont confrontés à des données anormales. Pour détecter les anomalies, il suffit de définir un seuil d’erreur de reconstruction.
Conclusions
Ces modèles jouent un rôle crucial dans le projet en permettant des prévisions précises et la détection d’anomalies. Bien que je n’aie pas directement participé à leur développement, ce stage m’a offert une opportunité précieuse d’approfondir mes connaissances en machine learning et de comprendre l’importance de ces modèles dans des applications réelles. Ces outils permettent non seulement d’anticiper les tendances futures, mais aussi d’identifier des comportements inhabituels, contribuant ainsi à une prise de décision plus éclairée et proactive, ce qui est pertinent pour l’IoT.
3 - Travail effectué
Nous allons voir les réalisations faites pendant ce stage et les différentes fonctionnalités qui ont été implémentés
Nous allons voir les réalisations faites pendant ce stage et les différentes fonctionnalités qui ont été implémentées.
Réalisations
Comme indiqué dans la page sommaire, une première version du site a déjà été implémentée par le stagiaire précédent. Dans cette version, les fonctionnalités de qualification des données et de détection d’anomalies variables ont été mises en place. De plus, l’infrastructure nécessaire à l’hébergement web de l’application a été installée. Cette infrastructure est hébergée sur OVHCloud, utilisant une distribution Ubuntu 22.04, et l’application est déployée avec Flask.
Pour ce stage, les fonctionnalités manquantes devront être implémentées, notamment la simulation prévisionnelle, la détection d’anomalies systémiques, et l’étude d’impact. De plus, des améliorations de la qualité de vie (QOL) seront apportées.
3.1 - Simulation Prévisionnelle
Nous allons voir les réalisations faites pour la partie “Simulation Prévisionelle”.
L’implémentation de la prévision s’est faite de la même manière que les autres fonctionnalités : création du layout, définition des callbacks, et mise en place du container associé. Cette approche a été appliquée à toutes les nouvelles fonctionnalités.
Cette fonctionnalité vise à présenter les différents modèles disponibles pour la prédiction de variables telles que la température, la pression, la puissance, etc. Les modèles sont entraînés sur des données provenant de capteurs de Technilog, de clients, ou de sources artificielles. La fonctionnalité comprend deux onglets :
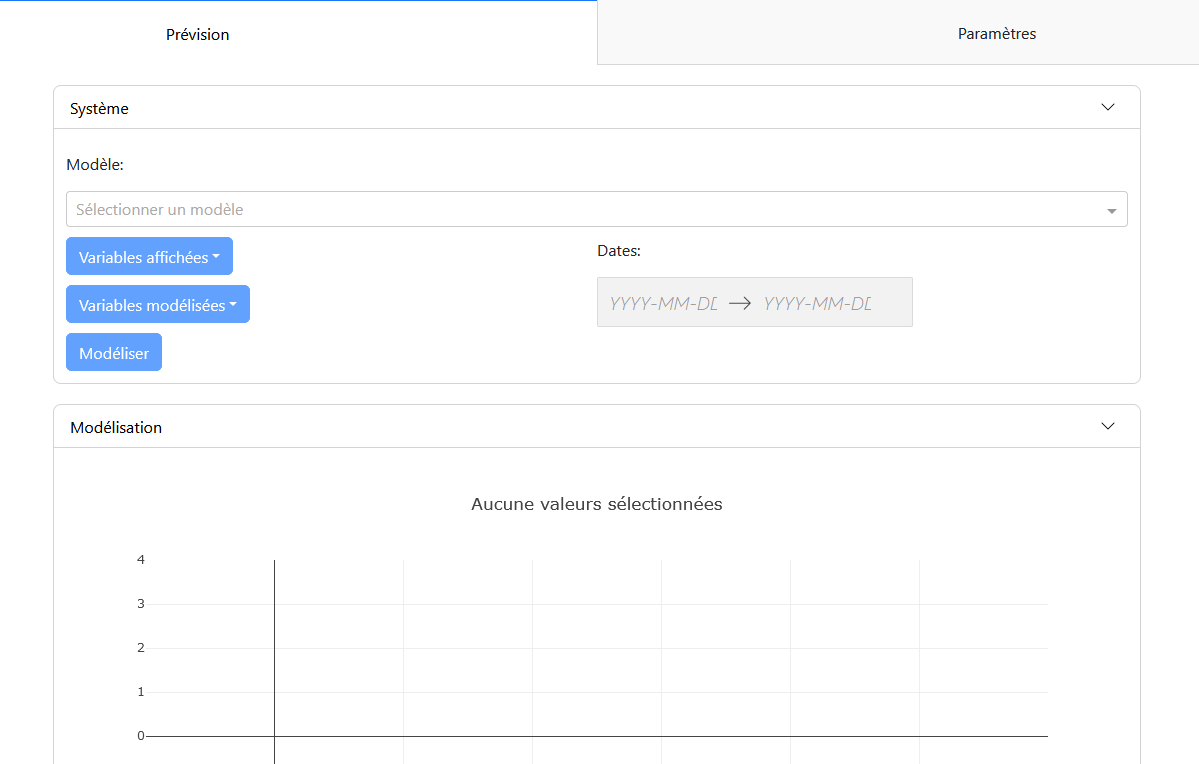
Onglet « Prévision » : Cet onglet contient le panneau de configuration « Système » et le panneau de modélisation « Modélisation ».
Panneau de Configuration : Permet de sélectionner les paramètres de modélisation, tels que le modèle, les variables d’entrée, les variables à afficher, les variables à modéliser, et la période d’étude. Une fois les variables sélectionnées, il est possible d’effectuer la prédiction et de visualiser la modélisation.
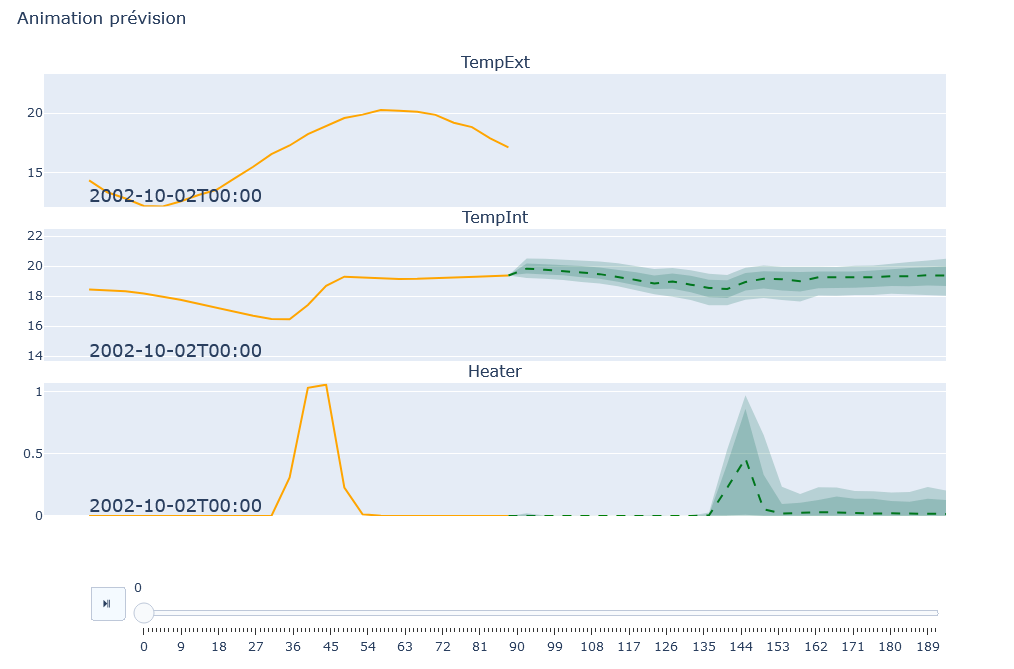
Panneau de Modélisation : Affiche les graphiques de modélisation pour chaque variable. Les graphiques montrent les données réelles en orange et les prédictions avec incertitude en vert. Des boutons de contrôle permettent de gérer l’animation, si cette option est activée.
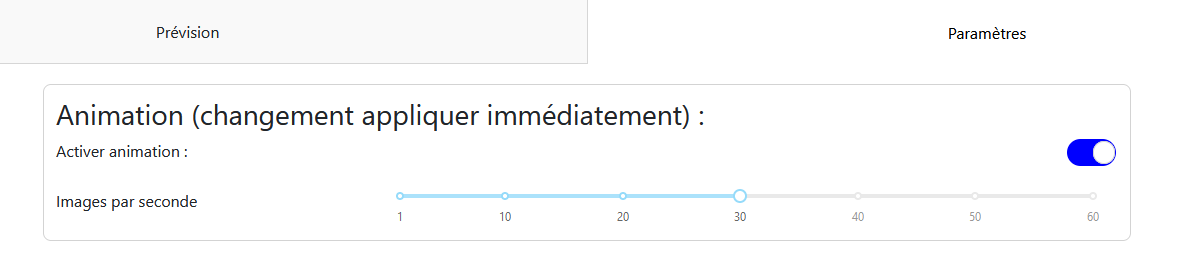
Onglet « Paramètres » : Contient les paramètres pour l’animation de la modélisation, tels que l’activation de l’animation et le nombre d’images par seconde. Ces options sont sauvegardées et appliquées à tous les modèles de la fonctionnalité.
3.2 - Détection d’anomalies de système
Cette fonctionnalité permet de détecter les anomalies en temps réel et dans les données historiques.
Pour la détection d’anomalies de système, trois onglets sont disponibles : « Temps réel », « Historique », et « Paramètres ». Les onglets « Temps réel » et « Historique » correspondent à différents cas d’utilisation de la fonctionnalité.
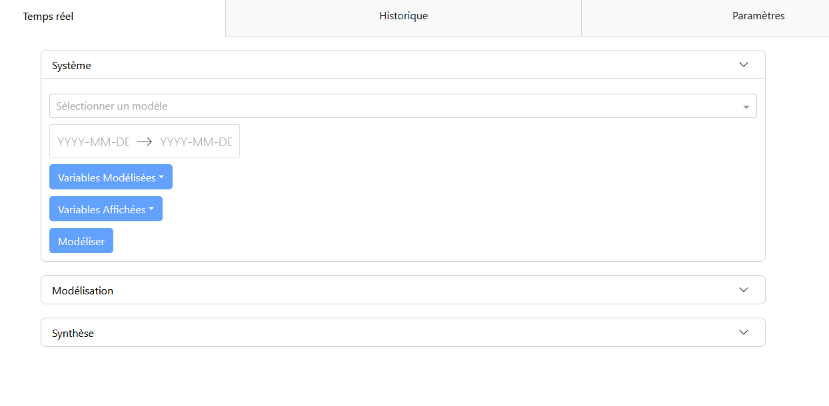
Onglet « Temps réel »
Dans l’onglet « Temps réel », on trouve les panneaux de configuration « Système », de modélisation « Modélisation », et de bilan « Synthèse ».
Panneau de Configuration : Permet de sélectionner le modèle, les variables modélisées (variables surveillées pour déterminer les anomalies), les variables affichées (variables visibles dans le panneau de modélisation), et la période de mesure (dates de début et de fin). Des valeurs par défaut existent en fonction du modèle sélectionné.
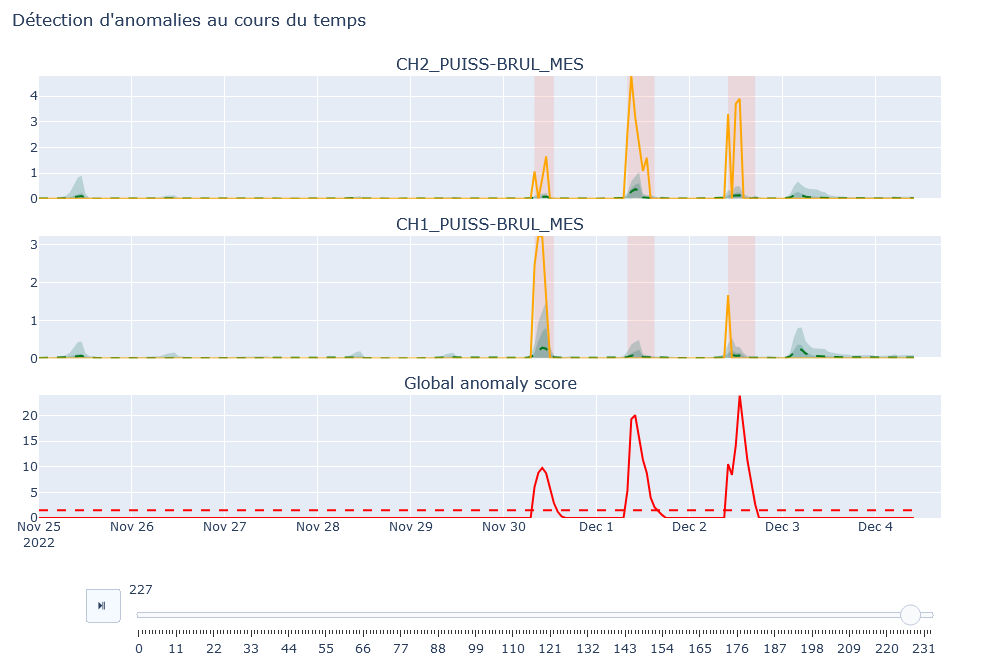
Panneau de Modélisation : Affiche les graphiques des valeurs sélectionnées avec leurs modélisations. Si le seuil d’anomalie est activé dans l’onglet « Paramètres », un graphique du score d’anomalie est également affiché, mettant en évidence les zones où le score dépasse le seuil.
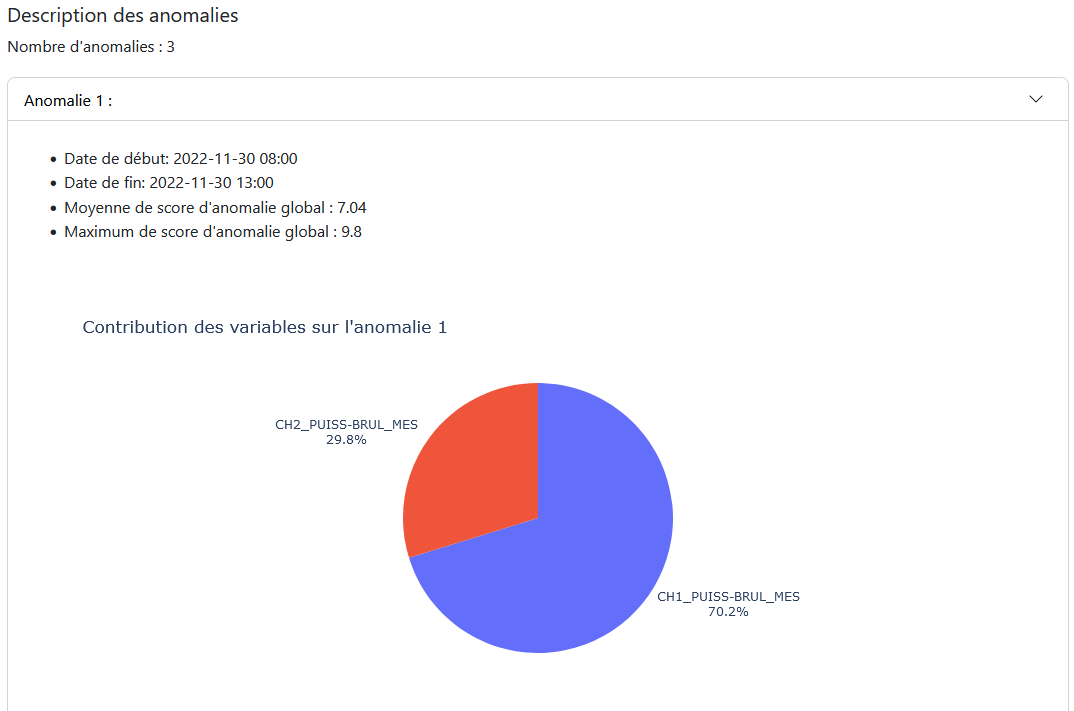
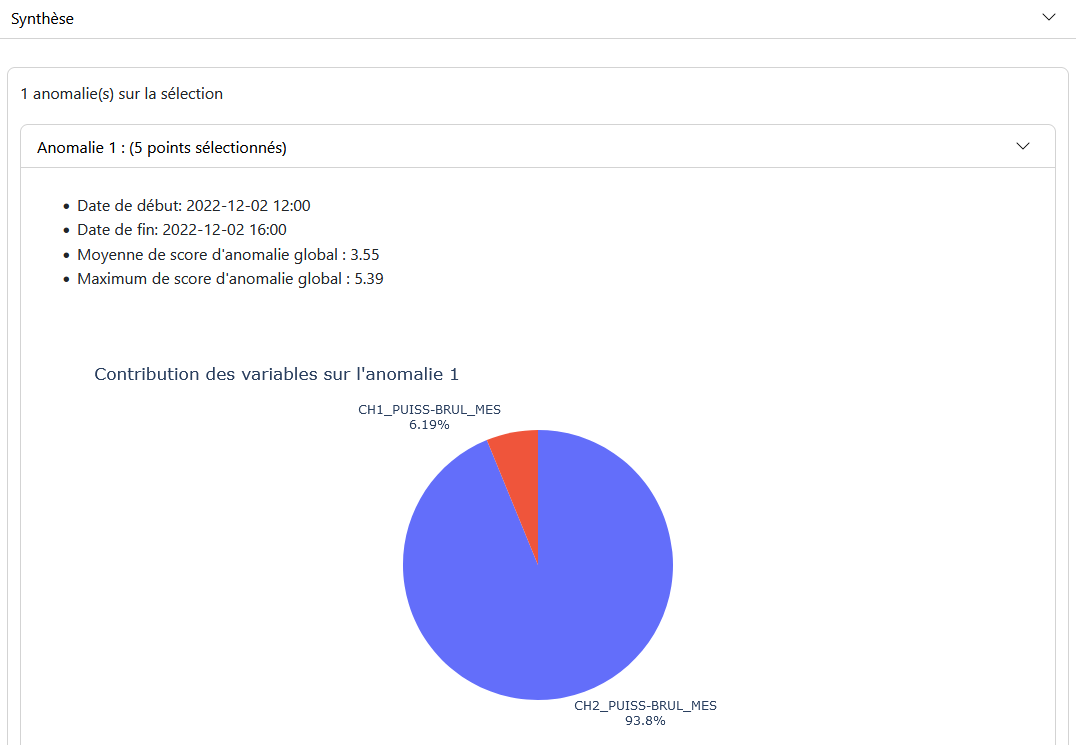
Panneau de Synthèse : Fournit une description des anomalies sur la période donnée et la contribution des variables modélisées à ces anomalies.
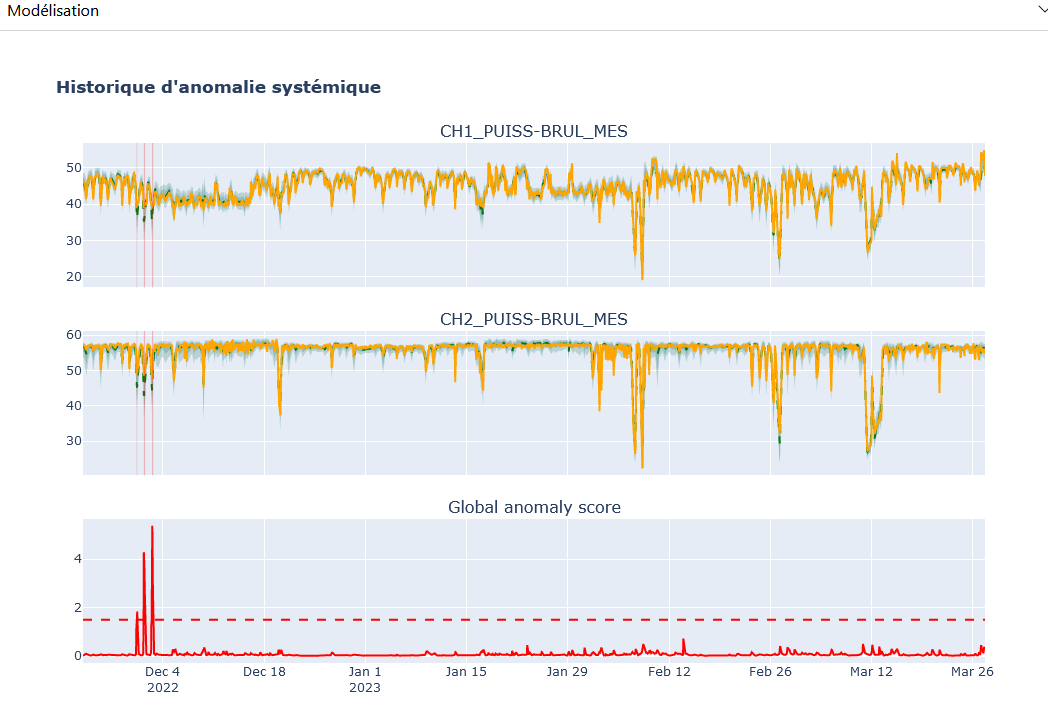
Onglet « Historique »
Dans l’onglet « Historique », on retrouve également les panneaux de configuration « Système », de modélisation « Modélisation », et de bilan « Synthèse ».
Panneau de Configuration : Similairement dans l’onglet « Temps réel » avec les mêmes choix. Permet de choisir le modèle, les variables modélisées, et les variables affichées. Contrairement au mode « Temps réel », il n’y a pas de sélection de période, car l’analyse couvre toute la période des données disponibles.
Panneau de Modélisation : Affiche les résultats en fonction des paramètres sélectionnés. L’utilisateur peut sélectionner une période spécifique en cliquant et en maintenant sur la modélisation obtenue.
Panneau de Synthèse : Affiche les résultats des anomalies pour la période sélectionnée, avec des descriptions des anomalies et la contribution des variables modélisées.
Onglet « Paramètres »
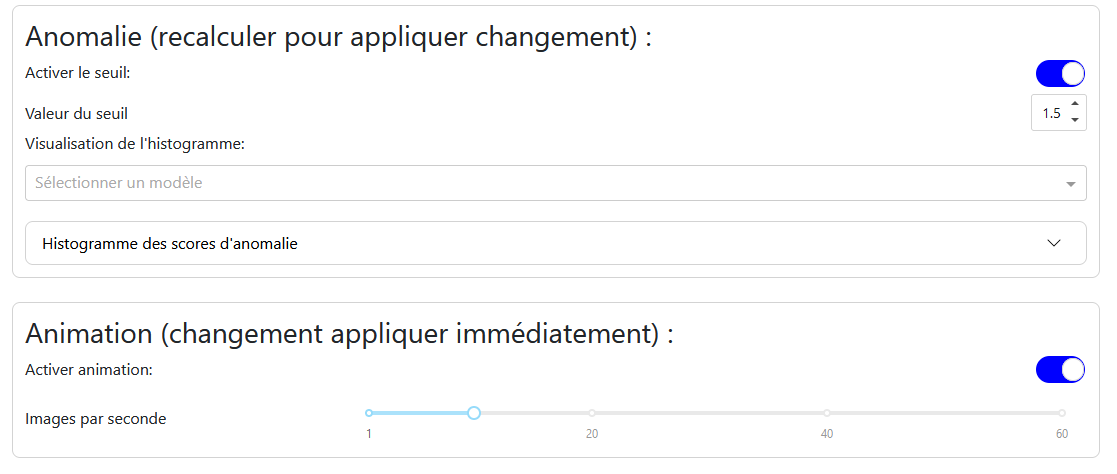
Anomalie : Permet d’activer le seuil d’anomalie et de définir sa valeur. Un histogramme des scores d’anomalie aide à déterminer la valeur optimale du seuil.
Animation : Permet d’activer ou de désactiver l’animation et de choisir le nombre d’images par seconde.
3.3 - Étude d’impact
Cette fonctionnalité permet d’analyser l’impact des variables et leurs influences mutuelles.
Cette fonctionnalité permet de visualiser l’impact d’une variable, c’est-à-dire les influences des variables entre elles. Elle permet ainsi d’observer les conséquences de la modification d’une ou plusieurs variables sur les autres.
L’interface se compose uniquement de l’onglet « Étude d’impact » avec les panneaux « Modélisation » et « Bilan ». Dans le panneau « Modélisation », on trouve les sous-panneaux « Sélection de l’étude d’impact » et « Impact des variables ».
Panneau de Sélection
Dans le panneau de sélection, l’utilisateur choisit l’étude d’impact souhaitée. Une fois l’étude sélectionnée, la modélisation s’affiche dans le panneau de modélisation.
Panneau de Modélisation
La modélisation de l’étude d’impact est présentée en deux parties :
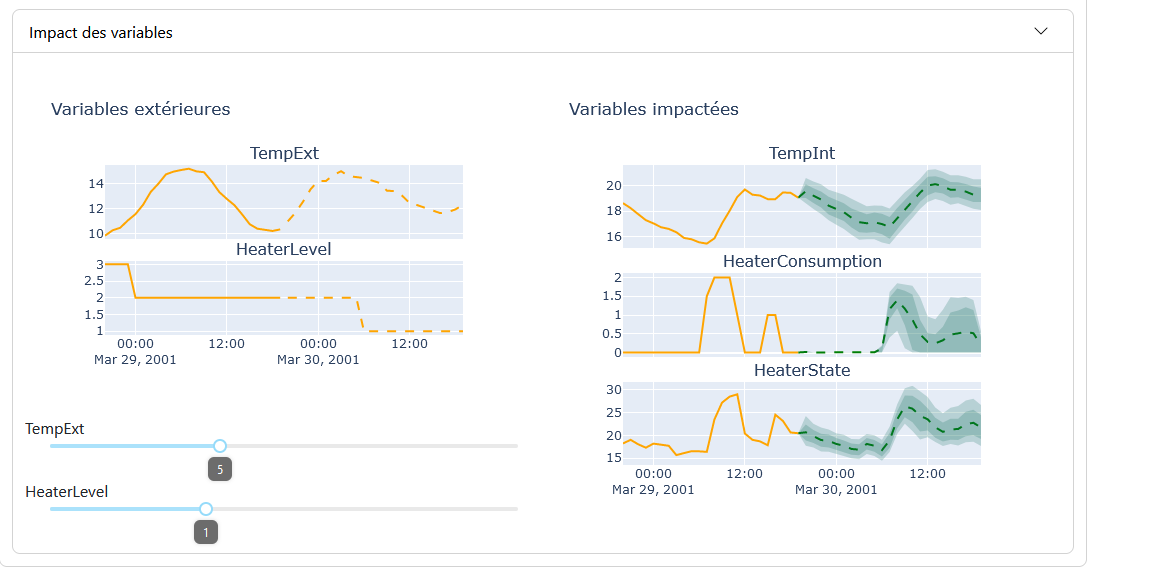
Variables Extérieures : Ce sont les variables hypothèses qui influencent les variables impactées. Elles sont ajustées via des curseurs (sliders).
Variables Impactées : Ce sont les variables qui changent en fonction des variables extérieures/hypothèses.
À chaque modification des valeurs des variables extérieures, les graphiques des variables impactées sont régénérés. Les graphiques de modélisation sont similaires à ceux de la fonctionnalité « Modélisation prévisionnelle », avec quelques différences : pour les graphiques des variables hypothèses, la partie du graphique avec prédiction et incertitude est remplacée par une section représentant les valeurs fixées par les curseurs.
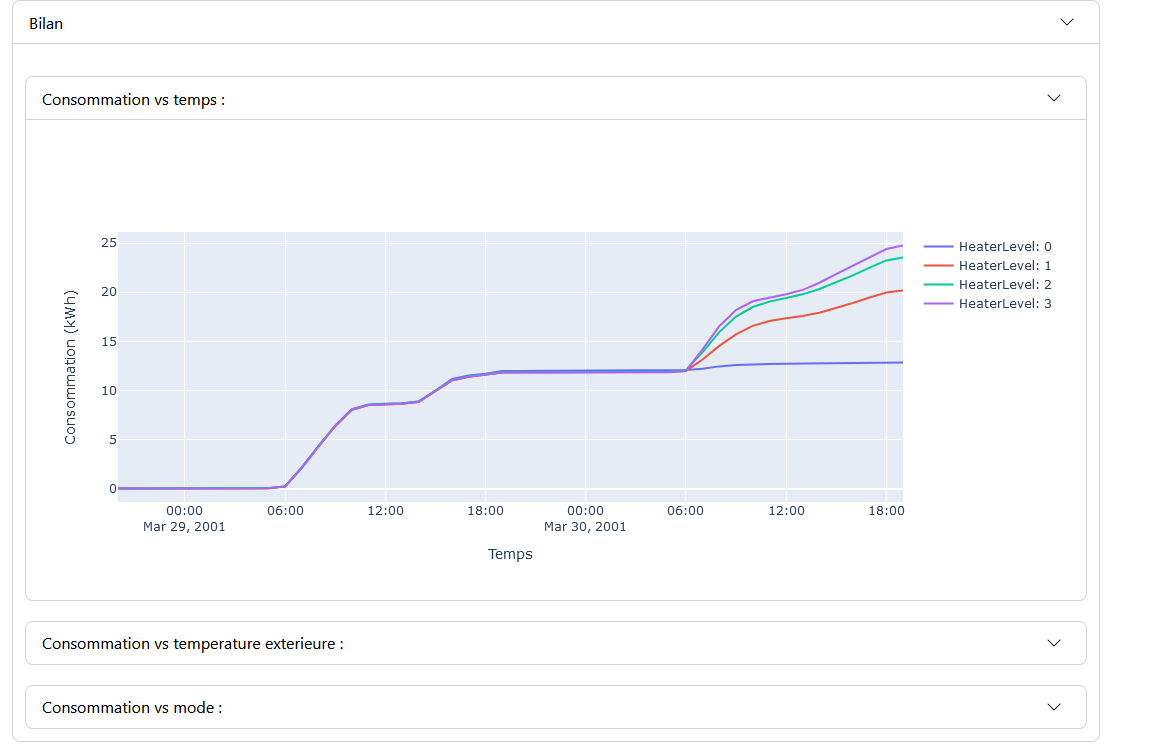
Panneau de Bilan
Dans le panneau de bilan, différents graphiques sont affichés en fonction de l’étude choisie. Ces graphiques mettent en évidence les liens et les impacts entre les variables. Lorsque les valeurs des curseurs sont modifiées, les résultats des graphiques changent en conséquence.
Comparaison avec d’autres fonctionnalités
Contrairement à d’autres fonctionnalités, il y a moins d’options disponibles (pas de choix de sélection pour la date/période ou les variables). Dans le contexte d’une application web démonstative, ces choix sont déterminés par le fichier de paramètres de l’étude.
3.4 - Mise à jour, QOL (« Qualities Of Life »)
Cette fonctionnalité permet d’ajouter et de mettre à jour les modèles disponibles, les fichiers de paramétrage, les jeux de données, et les fichiers de valeurs par défaut.
Mise à jour
La mise à jour permet d’ajouter et de mettre à jour les modèles disponibles, les fichiers de paramétrage, les jeux de données, et les fichiers de valeurs par défaut.
Onglets
Il y a trois onglets principaux :
Modèles : Permet de mettre à jour, d’ajouter, et de supprimer les modèles, ainsi que les études d’impact.
Jeux de données : Permet de mettre à jour, d’ajouter, et de supprimer des jeux de données.
Préconfiguration : Permet de modifier les valeurs par défaut des modèles pour leurs applications.
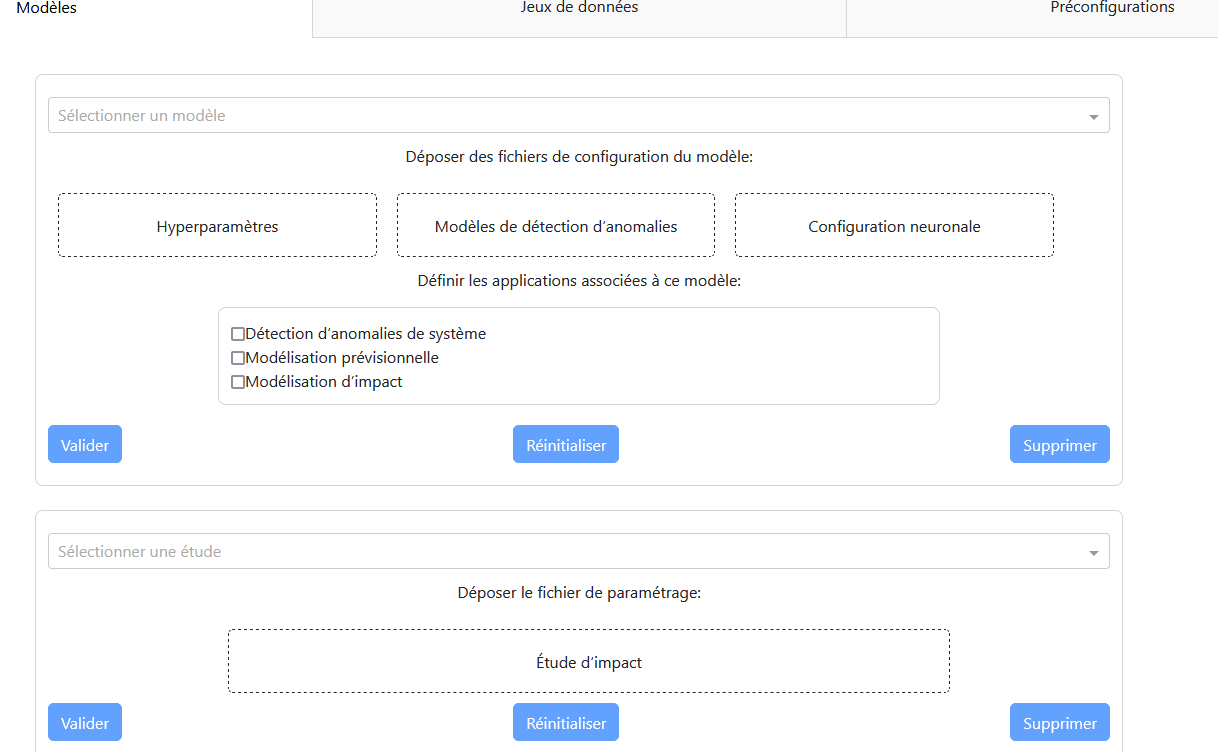
Onglet « Modèles »
Panneau Principal :
Un menu déroulant pour sélectionner le modèle.
Une zone pour déposer les fichiers nécessaires (modèle, hyperparamètres, configuration neuronale).
Une checklist pour sélectionner les applications associées au modèle.
Trois boutons : validation, réinitialisation, et suppression.
Mise à jour d’un Modèle :
Sélectionner le modèle à mettre à jour dans le menu déroulant.
Déposer les nouveaux fichiers de configuration.
Sélectionner les applications associées.
Confirmer avec le bouton « Valider ».
Ajout d’un Modèle :
Sélectionner « Nouveau modèle » dans le menu déroulant.
Déposer les fichiers nécessaires.
Sélectionner les applications associées.
Confirmer avec le bouton « Valider ».
Suppression d’un Modèle :
Sélectionner le modèle à supprimer.
Confirmer avec le bouton « Supprimer ».
Une boîte de dialogue demandera confirmation.
Étude d’Impact :
Un menu déroulant pour sélectionner l’étude.
Une zone pour déposer le fichier de configuration.
Trois boutons : validation, réinitialisation, et suppression.
Onglet « Jeux de données »
Panneau de Configuration :
Un menu déroulant pour sélectionner le jeu de données.
Une zone pour déposer le fichier de données.
Deux boutons : validation et suppression.
Modification/Ajout d’un Jeu de Données :
Sélectionner le jeu de données à modifier ou « Nouveau jeu de données ».
Déposer le fichier de données.
Confirmer avec le bouton « Valider ».
Suppression d’un Jeu de Données :
Sélectionner le jeu de données à supprimer.
Confirmer avec le bouton « Supprimer ».
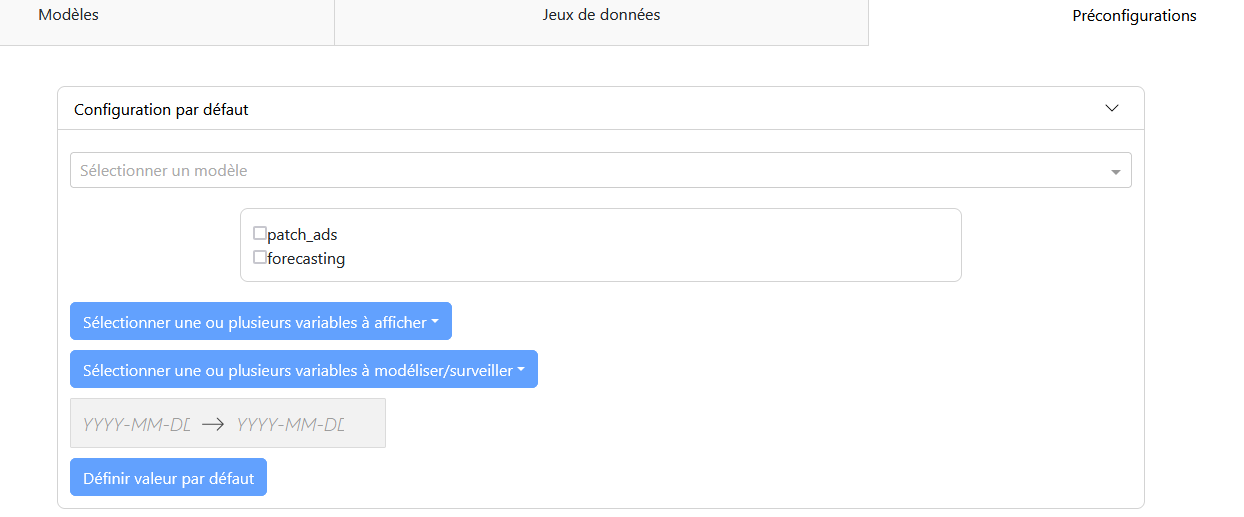
Onglet « Préconfiguration »
Panneau de Configuration :
Un menu déroulant pour sélectionner le modèle.
Une checklist pour sélectionner le cas d’application.
Sélection des variables à afficher et à modéliser.
Sélection de la période d’étude.
Un bouton de validation « Définir valeur par défaut ».
Configuration des Valeurs par Défaut :
Sélectionner le modèle et le cas d’application.
Configurer les paramètres de modélisation (variables affichées, modélisées, période).
Confirmer avec le bouton « Définir valeur par défaut ».
Types de Fichiers
Modèles : Fichiers .tpkl pour les modèles et .json pour les hyperparamètres.
Études d’Impact : Fichier Python avec les configurations pour l’étude.
Jeux de Données : Fichiers .csv contenant les informations utilisées par les modèles pour les prédictions.
Préconfigurations : Fichier .json avec les valeurs associées aux modèles et à la fonctionnalité utilisée.